AI CERTS
1 hour ago
Metacognitive AI: Alibaba Metis Cuts Redundant Tool Calls 96%
Additionally, we examine architecture demands, business impact, and lingering risks. Professionals seeking practical skills will also find a certification resource. Meanwhile, the story offers context from the April 2026 paper release. Finally, readers gain clear guidance on adopting Metacognitive AI strategies in production.
The Hidden Efficiency Problem
Many agents overuse external tools even when internal knowledge suffices. Consequently, each unnecessary API call adds latency, context noise, and cloud cost. VentureBeat reported some pipelines wasting 98% of calls before refinement. Metacognitive AI, exemplified by Metis, tackles this waste by teaching abstention.
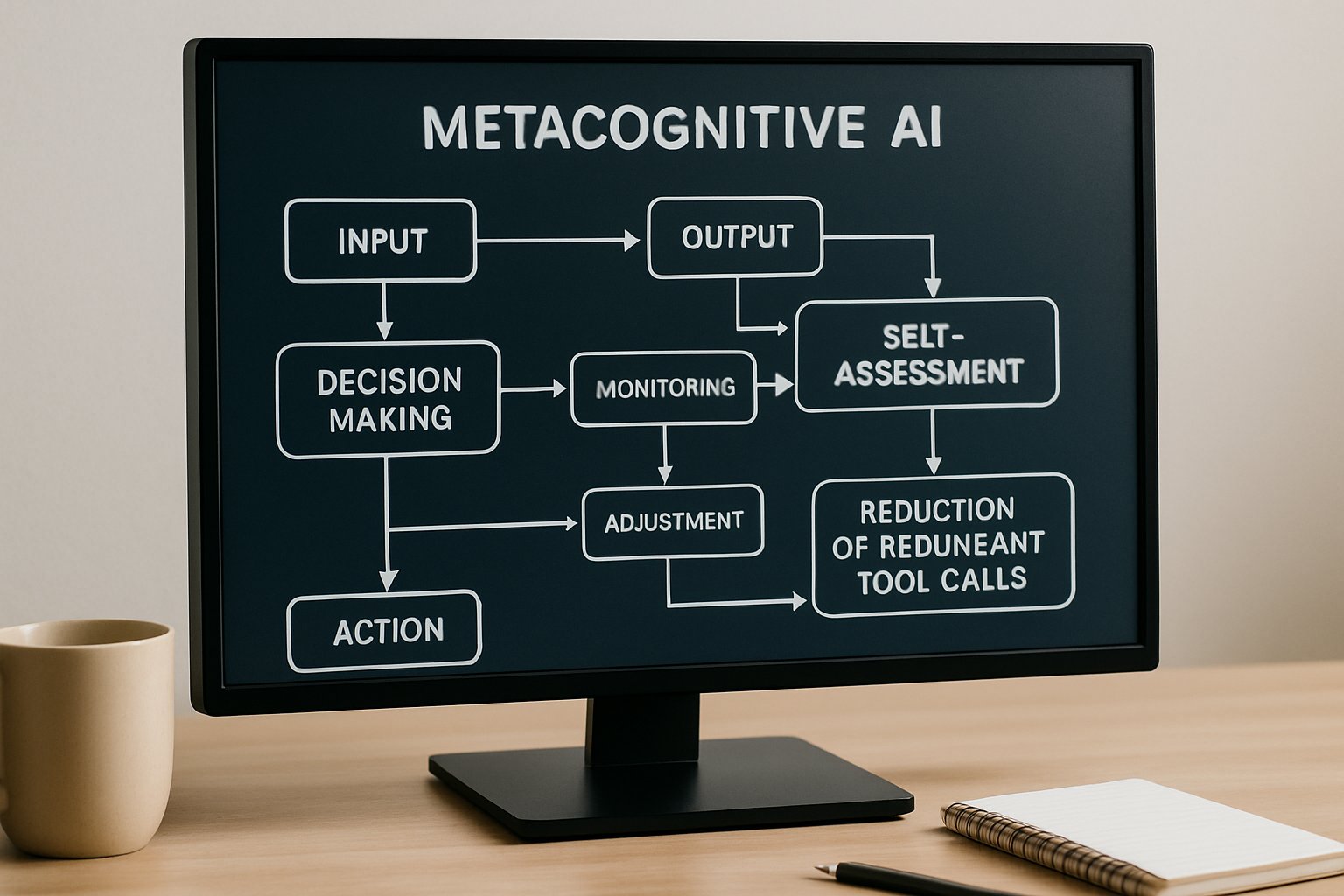
Traditional reward shaping penalized tool use together with answer quality. However, that coupled approach often hurt Accuracy because Metacognitive AI remained undeveloped. Engineers needed an Optimization method that separates correctness from frugality. The Accio team engineered that separation, leading directly into HDPO.
These insights reveal the scale of hidden inefficiencies. In contrast, the next section explains HDPO's targeted solution.
Inside HDPO Training Strategy
HDPO stands for Hierarchical Decoupled Policy Optimization. The recipe creates two reward channels: one for Accuracy, one for efficiency. Importantly, the efficiency penalty triggers only when the answer is already correct. Therefore, the agent first masters solutions, then learns restraint.
Training employed the Qwen3-VL-8B-Instruct backbone with roughly 5,000 prompts. Moreover, rollouts per prompt numbered 16, and batch size hit 128 samples. Weighting favored Accuracy at 1.0 while setting the tool penalty to 0.15. Such numbers illustrate deliberate Optimization toward balanced objectives.
HDPO equips Metacognitive AI with goal clarity without complex heuristics. Subsequently, benchmark scores tell the quantitative story.
Crucial Benchmark Score Numbers
Metis posted standout results across perception and reasoning suites. For example, WeMath jumped from 38.8 to 65.2 points, a 26-point leap. Meanwhile, V*Bench reached 91.1, and HR4K hit 83.5. Moreover, redundant tool calls plunged from 98% to 2%.
- Tool call reduction: 98% → 2% on internal tests.
- Perception metrics peaked at 91.1 on V*Bench.
- Efficiency score increased 46× compared with baseline agents.
- MathVista reached 78.0, topping several peer models.
These metrics demonstrate that Metacognitive AI eliminating noise often lifts Accuracy rather than harming it. Consequently, Metacognitive AI proves practical, not theoretical here. The numbers confirm HDPO's balanced Optimization. Nevertheless, hardware demands still matter, as the following section outlines.
Architecture And Compute Needs
Training Metis remained compute intensive. The public repo recommends eight 180-gigabyte GPUs or a matching multi-node cluster. Additionally, a separate judge model must run concurrently to assess correctness. That judge often uses a powerful LLM like Gemini 3.1 Pro.
Apache-2.0 code simplifies orchestration but cannot shrink memory footprints. Nevertheless, engineers can downscale experiments by reducing prompt counts and batch sizes. Careful Optimization of loading strategies also trims GPU overhead. Professionals can validate inference without full retraining using provided checkpoints.
Infrastructure requirements remain the chief barrier for many teams. However, evaluating risks and caveats provides additional perspective.
Key Risks And Caveats
Every Metacognitive AI system inherits judge biases. Biases in automated scoring may steer policies toward brittle behaviors. In contrast, manual evaluation scales poorly and inflates costs. Moreover, benchmark settings differ from unpredictable production traffic.
Misaligned judge thresholds could wrongly reward abstention, hurting Accuracy. Furthermore, the decoupled rewards assume stable signal quality across domains. The team mitigates issues with sandboxed execution and failure filters. Nevertheless, reproducibility still demands significant experimentation.
These caveats urge careful validation before deployment. Consequently, leaders must weigh risks against business gains presented next.
Critical Business Impact Metrics
Fewer tool calls directly lower external API fees. Therefore, organizations achieve faster response times, enhancing user satisfaction. Internal estimates suggest a 40% latency drop in prototype deployments. Additionally, trimmed context improves model focus, further boosting precision.
Cost models from Accio infer savings scale with API pricing tiers. Moreover, improved precision reduces downstream error handling workloads. Executives value these outcomes because they link Metacognitive AI to tangible ROI. Professional growth also matters; skill programs now address this paradigm.
Professionals can enhance their expertise with the AI Prompt Engineer™ certification. Financial and operational gains reinforce HDPO's relevance. Subsequently, we explore upcoming research directions.
Future Research Directions Ahead
Researchers plan to test Metis on live customer workloads. Furthermore, they intend to examine judge sensitivity sweeps and alternative backbones. Cross-domain studies could show how Metacognitive AI generalizes to code execution tasks. Open-source checkpoints invite community replication, despite compute hurdles.
Another priority involves integrating robustness audits into the training loop. Moreover, dynamic reward weighting may adapt Optimization to shifting objectives. Collaborative consortia could share compute credits, easing entry barriers. Nevertheless, security and governance guardrails must evolve alongside capability.
Forward-looking work will refine efficiency and safety together. Finally, we conclude with practical takeaways.
Metis shows that Metacognitive AI can deliver faster, cheaper, and smarter agents. By applying HDPO, developers decouple goals and achieve strong performance with higher Accuracy. Consequently, redundant tool invocations plummet from 98% to 2%, cutting cost and latency. Moreover, open Apache-2.0 code empowers replication and extension. Professionals should pilot modest inference tests, validate judge settings, and weigh compute budgets first. Additionally, they can upskill through the linked certification to secure strategic advantages. Take action now and explore Metacognitive AI solutions that think before acting.
Disclaimer: Some content may be AI-generated or assisted and is provided ‘as is’ for informational purposes only, without warranties of accuracy or completeness, and does not imply endorsement or affiliation.



