AI CERTS
3 months ago
Inside Anthropic’s November 20 service reliability incident
Meanwhile, DownDetector surge graphs spiked, reflecting thousands of frustrated reload attempts. Early visibility matters because outages erode trust and can introduce cascading failures across integrated systems. This report dissects the event, examines root causes, and outlines lessons for technical leaders. It also highlights security patches issued the same day and recommends proactive mitigation steps. Furthermore, professionals will find certification guidance that strengthens operational resilience.
Incident Timeline Overview
Anthropic began investigating at 08:10 UTC after alerts flagged elevated errors on Sonnet and Haiku variants. Subsequently, the team posted hourly updates until declaring full resolution at 12:03 UTC. The 3:30 AM ET disruption translated to 08:30 UTC for platform users watching the dashboard tick upward. Throughout the window, API success rates dipped well below the customary 99.5 percent baseline.
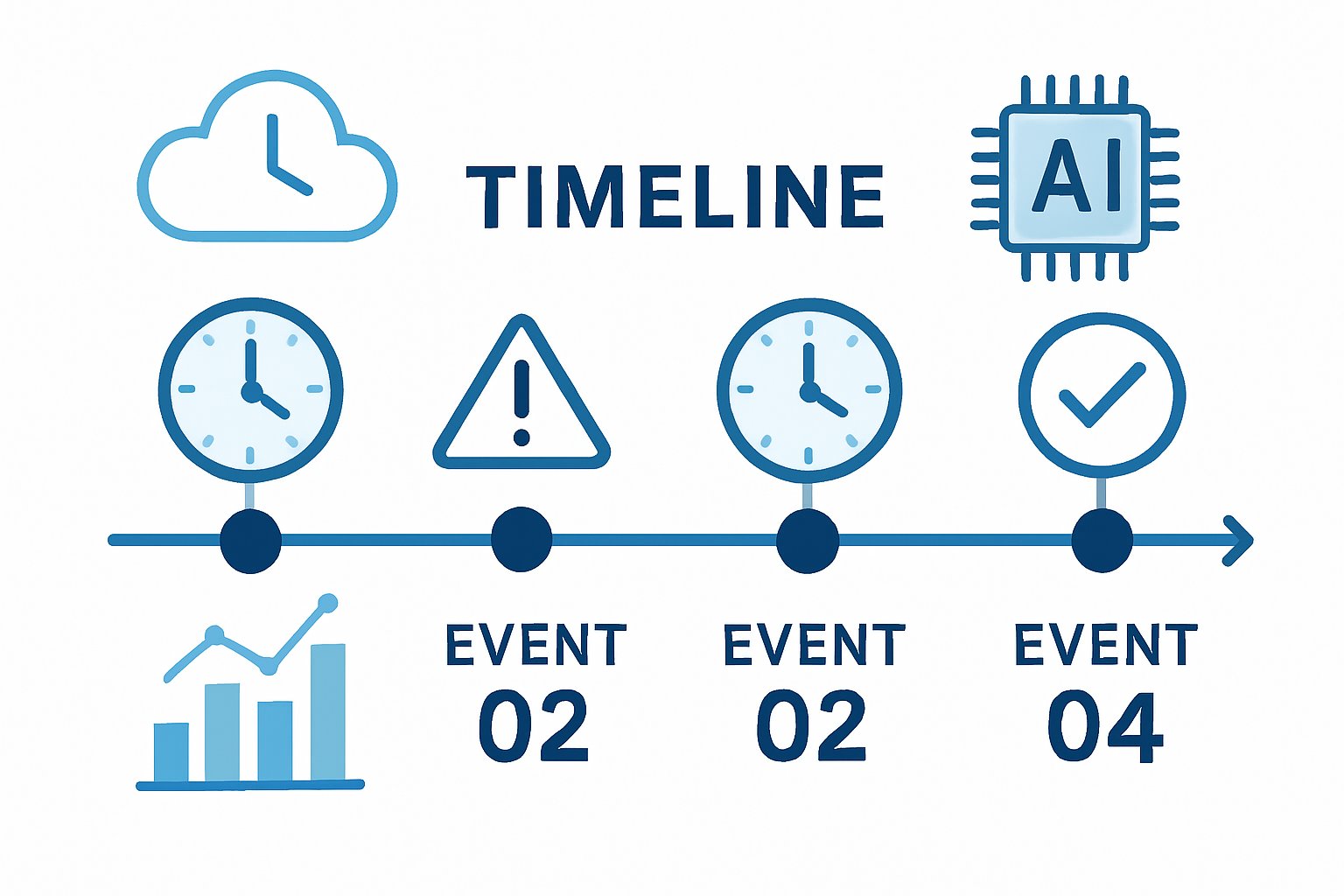
- 08:10 UTC – Investigating status created
- 09:10 UTC – Issue identified, fix prepared
- 10:15 UTC – Implementation progressing
- 11:03 UTC – Monitoring shows partial recovery
- 12:03 UTC – Resolved message posted
Moreover, independent trackers confirmed the same cadence, strengthening data triangulation. Nevertheless, some users reported lingering user access issues even after the status page turned green. In summary, the outage lasted roughly four hours from first alert through verification. These timestamps give operators crucial context for SLA evaluation. However, timeline data tells only part of the story, so deeper cause analysis follows.
Root Cause Signal Analysis
Status messages referenced elevated error rate without citing a network provider or internal rollback. In contrast, previous incidents often blamed third-party routing glitches. Therefore, engineers believe the November 20 anomaly stemmed from model serving orchestration within Anthropic’s cluster. Community sleuths pointed at a recently deployed batching tweak that touched request queues for Sonnet 4.5. Additionally, the high-severity CVE-2025-64755 patch landed hours later, suggesting parallel release trains. No evidence indicates a direct link, yet overlapping timings will fuel platform stability concerns among risk teams.
Consequently, many customers requested a full postmortem to clarify root mechanisms and preventive controls. Anthropic has not published that narrative at press time. Nevertheless, available logs hint that request router saturation triggered cascading retries, compounding latency. Root signals emphasize internal orchestration complexity more than external vendor failure. These clues set the stage for exploring concurrent security actions. Subsequently, we examine the same-day patch cycle.
Security Patch Context Details
Alongside the outage, Anthropic shipped Claude Code version 2.0.31 to neutralize a sed parsing vulnerability. The flaw allowed arbitrary file writes, scoring 8.7 on the CVSS scale. Furthermore, GitHub advisory GHSA-x9qc confirmed auto-update channels would distribute fixes within hours. Security researcher Adam Chester received credit for responsibly disclosing the bug weeks earlier.
Meanwhile, Anthropic stated no exploitation had been observed in the wild. Nevertheless, the proximity between code patching and the service reliability incident heightened scrutiny from compliance auditors. Industry veterans warn that simultaneous production and security changes can increase blast radius if governance falters. Consequently, risk teams often stagger such releases to minimize compound failure modes. The patch narrative underscores Anthropic’s prompt response to integrity threats. Still, overlapping timelines complicate root attribution. Next, we review real-world community impact metrics.
Community Impact Data Points
Reddit threads filled quickly with screenshots of stalled prompts and API stack traces. Moreover, a marked DownDetector surge logged thousands of error reports across North America and Europe. Another responder wrote that the chatbot produced blank outputs for five consecutive attempts. Independent monitor IsDown displayed red bars matching the status page timeline. Consequently, enterprise SRE teams activated contingency plans, including queued retries and temporary feature toggles. Several startups flagged user access issues in customer-facing dashboards, prompting proactive social media notices. In contrast, some Asia-Pacific tenants observed minimal degradation due to regional replication buffers. Despite brief duration, confidence dipped, reinforcing platform stability concerns voiced during prior November events. Community data validates that even four-hour blips ripple across many workflows. These experiences guide the reliability lessons discussed next. Therefore, the broader industry pattern merits inspection.
Reliability Trends Landscape Overview
Outage clusters appeared on November 17, 18, and 20, hinting at rollout friction during feature accelerations. In contrast, Anthropic advertises 99.53 percent uptime over ninety days, mirroring rival LLM providers. However, incidents remain acutely visible because conversational agents occupy critical user journeys. Gartner research claims each ninety-minute outage costs midsize SaaS vendors up to $300,000 in lost productivity.
Moreover, the November window overlapped with Black Friday preparation, amplifying economic stakes. Subsequently, CIOs highlighted platform stability concerns during board briefings and vendor risk evaluations. Industry watchers expect tighter contractual SLAs that include clearer response time targets for any service reliability incident. Consequently, vendors must balance rapid innovation with disciplined release engineering. Pattern analysis reveals recurring but improving recovery times. Yet stronger mitigation practices remain vital. Accordingly, the following guide lists practical safeguards.
Mitigation Best Practice Guide
SRE leaders recommend layered defenses that limit fallout when LLM endpoints misbehave. Additionally, enterprise architects can adopt circuit breakers that shift traffic to cached responses. Developers should log granular model IDs to detect partial outages affecting specific Sonnet versions. Furthermore, recurring chaos engineering drills verify rollback mechanisms and alert calibrations.
- Implement exponential backoff for retry storms.
- Diversify vendor footprint to avoid single-provider dependency.
- Encrypt and audit code agents regularly.
- Enroll engineers in the AI Cloud Practitioner™ program for updated best practices.
Moreover, adopting periodic third-party audits reduces blind spots highlighted by the recent 3:30 AM ET disruption. Such actions prepare teams for every future service reliability incident, regardless of origin. Nevertheless, cultural reinforcement is as important as tooling. These practices shorten mean time to recovery and protect revenue. The next section turns recommendations into concrete action items. Meanwhile, strategic planning remains paramount.
Forward Looking Action Items
CIOs should request detailed postmortems that quantify scope, root cause, and prevent recurrence. Consequently, Anthropic’s transparency will shape customer loyalty during competitive procurement cycles. Contracts must specify credits triggered by any prolonged service reliability incident beyond agreed thresholds. Furthermore, boards expect scenario planning that covers 3:30 AM ET disruption patterns coinciding with global business hours. Teams should monitor DownDetector surge signals as early indicators, complementing internal alert flows.
Additionally, quarterly tabletop exercises must rehearse response to highway-level user access issues. Investors increasingly penalize firms that ignore accumulating platform stability concerns. Therefore, keeping an updated skill portfolio is wise. Professionals can reinforce that portfolio through the AI Cloud Practitioner™ credential, which emphasizes resilient architecture. Subsequently, organizations gain staff capable of mitigating every documented service reliability incident. Action items tie governance, tooling, and education into a unified reliability program. These steps conclude the core analysis. Finally, we synthesize key lessons.
The November 20 event reminds every operator that a service reliability incident can strike without warning. However, rapid detection, transparent communication, and disciplined rollbacks kept the disruption brief. Community metrics, including the final DownDetector surge, validated Anthropic’s recovery timeline. Nevertheless, scattered user access issues persisted, showing the tail risk of even small outages.
Organizations must treat each service reliability incident as a rehearsal for the next global test. Therefore, codifying playbooks for 3:30 AM ET disruption scenarios will accelerate future containment. Consequently, leaders should revisit contracts, strengthen observability, and pursue continuous learning. Pursuing the AI Cloud Practitioner™ course equips teams to anticipate any upcoming service reliability incident and safeguard revenue. Ultimately, consistent drills convert a service reliability incident from a crisis into a controlled experiment.



