
AI CERTs
2 months ago
How Software Reliability Scoring Engines Disrupt Cloud SLAs
Cloud executives face escalated pressure to guarantee nonstop service availability. Consequently, contracts now demand transparent and enforceable reliability metrics. Software reliability scoring engines promise that clarity by distilling thousands of telemetry points into a single 0–100 number. The concept is simple yet disruptive. Vendors like Gremlin, Nobl9, and ScoutITAi package chaos tests, SLO rollups, and predictive analytics into board-level dashboards. Meanwhile, investors see the trend as a billion-dollar expansion of the observability market. Furthermore, standards such as RFC 9544 reinforce the push toward precise, comparable measurements. In contrast, legal teams worry about black-box algorithms driving monetary penalties. This article traces the rise of software reliability scoring engines, examines their mechanics, and evaluates their contractual impact. Readers will also learn how uptime forecasting and DevOps risk metrics feed these scores and what steps ensure safe adoption.
Market Shift Explained Clearly
Until recently, SRE dashboards focused on isolated SLO charts. However, market expectations changed rapidly. Investors, boards, and regulators demanded an executive-ready indicator. Software reliability scoring engines emerged as the answer. Gremlin launched its Reliability Score in late 2023, averaging redundancy, scalability, and dependency tests. Moreover, Nobl9 followed with Reliability Center, rolling thousands of SLOs into composite metrics. Analyst reports forecast the AI observability subsegment will triple to USD 3 billion by 2035. Consequently, venture funding accelerates toward vendors promising decision-grade scores. Meanwhile, standards groups recognize the shift and formalize measurement rules. These developments confirm a structural market pivot. Therefore, teams must understand the mechanics behind the headline number.
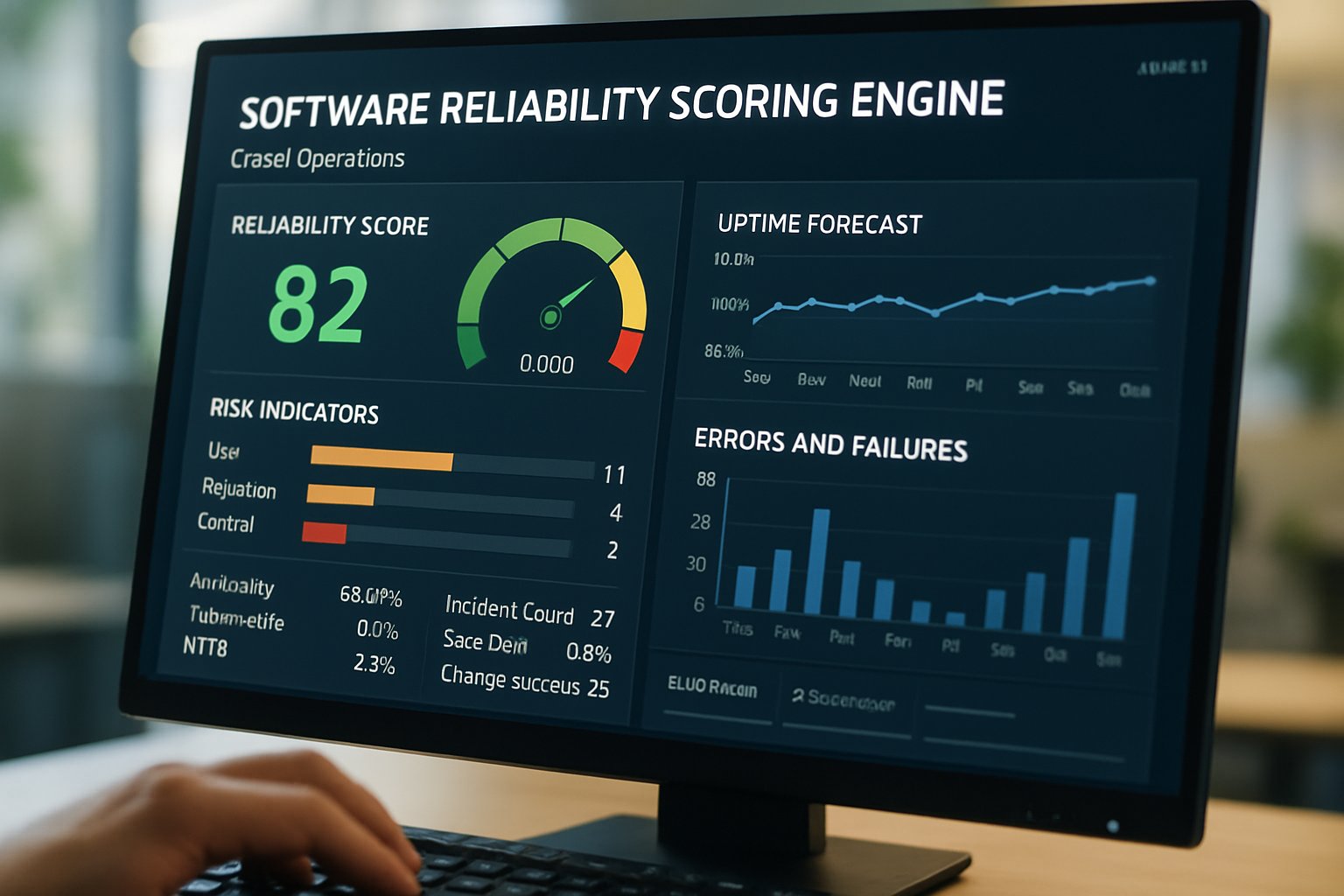
Scoring Engine Mechanics Overview
Inside each platform, telemetry feeds, synthetic tests, and change logs flow into a weighting algorithm. These software reliability scoring engines follow a predictable data pipeline. Gremlin assigns numeric points to chaos experiment outcomes and divides results across four categories. Nobl9 instead converts SLO compliance percentages into a composite hierarchy. In contrast, ScoutITAi patents its Reliability Path Index and shields the formula from auditors. Nevertheless, all approaches rely on uptime forecasting modules that predict near-future availability. Additionally, machine-learning models correlate DevOps risk metrics such as deployment frequency and rollback rate. The combined signals produce a 0–100 reliability score accessible through APIs and dashboards. Therefore, practitioners must request clear documentation showing input sources, math, and version history. Such transparency limits disputes when automated actions trigger. Next, we examine contractual impact.
Operational Impact On SLAs
Legal teams traditionally embedded rigid SLA clauses with manual dispute processes. However, dynamic reliability scores now promise automatic enforcement. When a score falls below a set threshold, some platforms pause deployments or issue credits. Consequently, release freezes can occur minutes after risky code hits production. Gremlin reports customers using its score reduced major incidents by 20 percent over six months. Meanwhile, Nobl9’s composite metrics feed board slides that compare services on a single page. Uptake of uptime forecasting boosts confidence because executives see projected risk, not just past failure. Moreover, DevOps risk metrics link engineering behavior to contractual exposure, aligning developers with finance goals. These software reliability scoring engines therefore convert technical noise into monetary signals. Nevertheless, auditors warn that opaque computations can expose providers to legal challenges. Therefore, contracts must reference auditable SLIs, algorithm change policies, and evidence retention periods. Clear terms maintain fairness for both sides. Standards efforts reinforce that need.
Emerging Standards And Research
Industry bodies recognise the measurement gap. Consequently, the IETF released RFC 9544, defining precision availability metrics for distributed services. The document specifies sampling windows, percentile calculations, and reference clocks. Moreover, the OpenSLO community pushes a vendor-neutral spec for declarative SLO files. Academic labs move further, exploring agentic SRE frameworks that adjust configurations autonomously. STRATUS and MSARS papers describe reinforcement learning agents that monitor uptime forecasting outputs and initiate mitigations. Additionally, researchers test DevOps risk metrics as reward signals, encouraging safer deployment patterns. These experiments suggest that software reliability scoring engines will soon feed automated remediation loops. Nevertheless, standards trail product innovation, leaving buyers to negotiate custom terms. Therefore, practitioners should map vendor metrics to RFC 9544 fields and demand proof-of-concept integrations. Such diligence ensures future interoperability while innovation continues. Benefits and risks deserve scrutiny.
Key Benefits And Drawbacks
Executives admire the clarity, yet engineers remain cautious. The following bullets summarize advantages and concerns around software reliability scoring engines.
- Unified score simplifies board communication and vendor comparison.
- Proactive tests uncover risks before customer outages.
- Uptime forecasting offers predictive alerts for capacity planning.
- Opaque formulas can mask critical subsystem failures.
- Vendor lock-in risk grows when indices remain proprietary.
- Overreliance on a single number can erode nuanced SRE practices.
These points reveal a balanced picture. Consequently, pragmatic adoption guidance follows.
Effective Adoption Best Practices
Successful teams treat the score as guidance, not gospel. They combine automated testing with human judgment. These software reliability scoring engines require disciplined operational processes. Additionally, they maintain evidence for every calculation to satisfy auditors. First, capture raw telemetry in immutable storage for at least thirteen months. Second, version the scoring algorithm and publish change logs. Third, map each SLI to RFC 9544 fields for contractual clarity. Moreover, integrate DevOps risk metrics dashboards to reveal behavioral trends that may skew scores. Rotating chaos experiments weekly prevents stale data and improves predictive power. Practitioners should also align uptime forecasting windows with business cycles to avoid false alarms. Professionals can enhance their expertise with the AI Prompt Engineer™ certification. The program sharpens skill in prompt design and automated observability queries. These steps foster resilient operations and trustworthy reporting. Consequently, organizations embed scores confidently in governance processes. The future outlook now warrants attention.
Strategic Future Outlook Roadmap
Market signals suggest wider rollout is imminent. Gartner peers expect board dashboards to standardize on software reliability scoring engines within two years. Moreover, cloud providers will likely embed software reliability scoring engines directly into platform terms, issuing automatic credits. In contrast, open-source communities will release lightweight software reliability scoring engines that companies can self-host. Consequently, competitive pressure will force algorithm transparency and cross-vendor comparability. Standards bodies may certify reference datasets, enabling neutral benchmarking across tools. Meanwhile, AI copilots will interpret scores, generate remediation pull requests, and adjust capacity autonomously. Therefore, legal teams should prepare contract templates that anticipate continuous algorithm updates. Forward-looking SRE leaders must pilot predictive alert routing guided by validated models. Organizations that act now will reduce incident cost while gaining negotiation leverage. These predictions highlight rising stakes. Therefore, timely preparation becomes a competitive weapon.
Reliability management is entering a quantitative era. Executives crave one metric, engineers need actionable evidence, and legal teams require auditability. Recent vendor releases, new standards, and academic advances prove the shift is real. However, clarity demands discipline. Publish SLIs, version algorithms, and store evidence before linking scores to financial penalties. Moreover, align predictive models with real business windows to avoid false alarms. Companies that implement these practices will cut incident costs and strengthen negotiating power. For deeper skills in automated observability and AI tooling, consider pursuing the AI Prompt Engineer™ certification. Start experimenting today and turn reliability into a strategic advantage.



