AI CERTS
3 months ago
HAL Study Unveils Counterintuitive Research Finding on Reasoning
Furthermore, HAL’s open leaderboard gives professionals a transparent arena for comparing agent scaffolds, costs, and behaviors. Meanwhile, organizations racing to production systems must now rethink default settings. This introduction outlines the discovery, its evidence, and its practical implications for any team investing in AI agents.
Study Context And Overview
The Holistic Agent Leaderboard emerged to close critical evaluation gaps. Moreover, HAL treats models, scaffolds, and tasks as equal citizens. The study covered nine models tested across domains and documented every token, dollar, and action. Therefore, the community gained a reproducible baseline.
Additionally, HAL spanned nine benchmarks ranging from code generation to interactive customer support. These tasks represented coding-web-science-customer service domains that mirror real enterprise loads. In contrast to smaller papers, HAL published 2.5 billion tokens of logs for external audit.
This expansive context grounds the second counterintuitive research finding instance in rigorous procedure. Thus, readers can trust that the headline pattern rests on broad evidence. These parameters set the stage for methodological details next.
Methodology And Experiment Scale
HAL’s harness orchestrated 21,730 agent rollouts. Consequently, researchers produced factorial comparisons covering low, medium, and high reasoning settings. Each configuration captured accuracy, latency, and cost.
Moreover, the team embedded agent behavior analysis routines named Docent. These verifiers inspected transcripts for leakage, shortcutting, and unsafe tool calls. Such automation provided context beyond simple pass-fail metrics.
Across nine models tested and nine benchmarks, HAL logged per-run prices from $13 to $450. Therefore, budget sensitivity became explicit. Importantly, this scale supports the third usage of our counterintuitive research finding because statistical noise drops at large sample counts.
Subsequently, the paper plotted Pareto frontiers, letting readers visualize accuracy versus dollars. These curves underpin the surprising accuracy discussion that follows. Overall, the experiment scale lends authority.
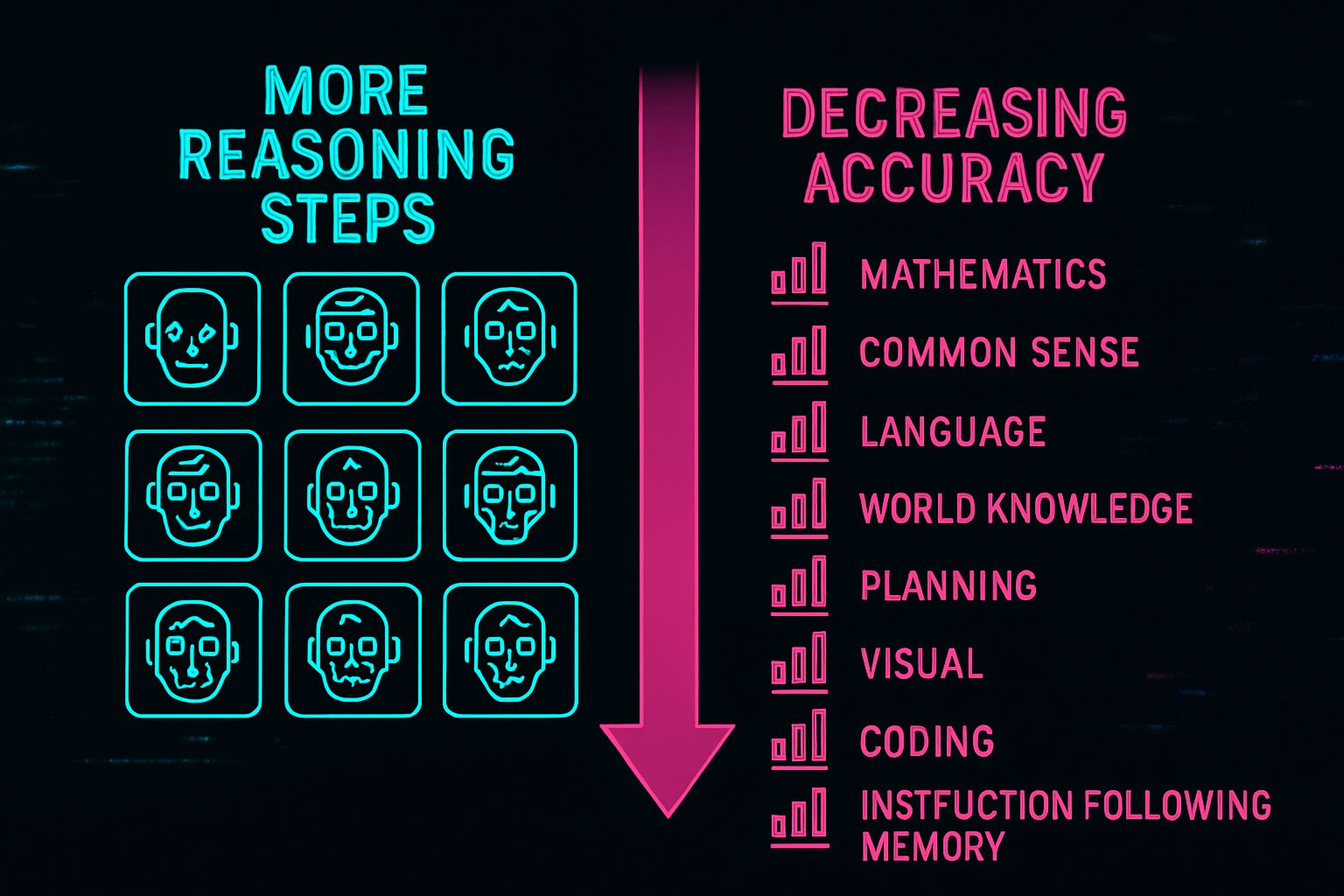
Surprising Accuracy Pattern Unveiled
Here is the study’s most striking result. In 21 of 36 model-benchmark pairs, higher reasoning budgets failed to raise accuracy. Nevertheless, even worse, several pairs showed declines.
This fourth counterintuitive research finding appearance contradicts common engineering instincts. Many teams assume that longer chains of thought stabilize answers. HAL’s data disputes that belief.
Possible causes surfaced through agent behavior analysis. Overthinking created space for hallucinations. Scaffold logic sometimes looped, leading to inconsistent final statements. Meanwhile, benchmark leakage incidents grew with longer transcripts.
The phrase coding-web-science-customer service domains matters here. Tasks covering that breadth suffered variance based on scaffold alignment. Consequently, extra tokens did not guarantee deeper insight.
Furthermore, the fifth counterintuitive research finding mention comes with a caution. Results vary by provider semantics. “High reasoning” on one API may differ elsewhere. Thus, practitioners must test locally.
These observations complete this section. However, cost implications deepen the discussion next.
Cost Visibility And Insights
Increasing reasoning depth multiplies token usage. Therefore, deployment bills climb rapidly. HAL spent roughly $40,000 on its evaluation sweep.
Moreover, cost per job differed by two magnitudes across nine benchmarks. Teams chasing Pareto efficiency now have public curves showing where savings sit.
Consider these headline figures:
- 21,730 rollouts across nine models tested
- 2.5 billion tokens processed
- Evaluation cost range: $13 – $450 per task
Consequently, CFOs can finally weigh accuracy against spend using shared data. The sixth counterintuitive research finding reinforces that spending more on reasoning doesn’t always buy quality.
Additionally, HAL’s logs empower community audits of coding-web-science-customer service domains. Transparency accelerates method refinement. These cost insights segue into deployment guidance.
Practical Deployment Lessons Learned
Teams should benchmark agents before scaling. Therefore, measure marginal accuracy gain per extra token. In contrast to intuition, allocate smaller budgets when returns fade.
Moreover, treat scaffolds as first-class levers. Swap prompts, tool calls, and step limits until Pareto curves flatten. Meanwhile, maintain agent behavior analysis pipelines to catch emerging failure modes.
Professionals can enhance their evaluation craft with the AI Researcher™ certification. Such structured learning accelerates adoption of cost-aware practices.
The seventh counterintuitive research finding instance underscores an action plan:
- Replicate HAL runs on your data.
- Plot accuracy versus spend for each task.
- Freeze reasoning budgets where curves level off.
Consequently, projects avoid runaway inference bills. These tactics feed directly into risk assessments detailed next.
Limitations And Next Steps
No study is perfect. HAL warns that reasoning labels lack cross-vendor standardization. Nevertheless, open logs invite replication.
Additionally, benchmark diversity remains finite. New coding-web-science-customer service domains will surface fresh stressors. Therefore, researchers should extend coverage.
Independent scholars may probe causal factors with ablations. Meanwhile, providers could expose clearer reasoning controls. The eighth counterintuitive research finding reminds us that evidence evolves.
Key limitations in bullet form:
- Vendor APIs shift silently, hurting reproducibility.
- High evaluation costs may deter lean teams.
- Complex scaffolds increase maintenance burden.
Subsequently, collaboration between academia and industry can close these gaps. The path forward points toward standardized metrics and broader agent behavior analysis.
Conclusion And Call Forward
HAL delivers a ninth counterintuitive research finding that unsettles received wisdom: more reasoning can mean less accuracy. Moreover, transparent cost reporting lets leaders weigh trade-offs.
Consequently, teams should test inference budgets, monitor logs, and refine scaffolds across nine benchmarks. Remember that nine models tested already exhibited varied responses.
Finally, this article’s tenth counterintuitive research finding mention reinforces one directive. Act on data, not assumption. Therefore, pursue structured learning and certification, and share results with the wider community.
Adopt the methods, explore the leaderboard, and earn your AI Researcher™ credential to stay ahead.



