AI CERTS
1 day ago
Google AI Overviews Face Scrutiny Over Patient Safety Risks
Meanwhile, Google claims the feature usually provides accurate and helpful health advice. However, the company has offered no granular data proving that assertion. Professional readers must therefore evaluate both technical performance and real-world healthcare risks. This article dissects the investigation, quantifies exposure, and outlines steps to mitigate future damage. Readers will gain statistical context, understand liability debates, and access skills to safeguard patients online.
Guardian Investigation Findings Overview
The Guardian’s 2 January investigation presented concrete examples of dangerous outputs. For instance, one overview told pancreatic cancer patients to avoid high-fat foods. Specialists stressed that such restriction undermines calorie intake needed for treatment tolerance. Another snippet displayed incorrect liver enzyme reference ranges, potentially reassuring sufferers who need urgent care. Google AI Overviews generated each cited statement, according to captured screenshots.
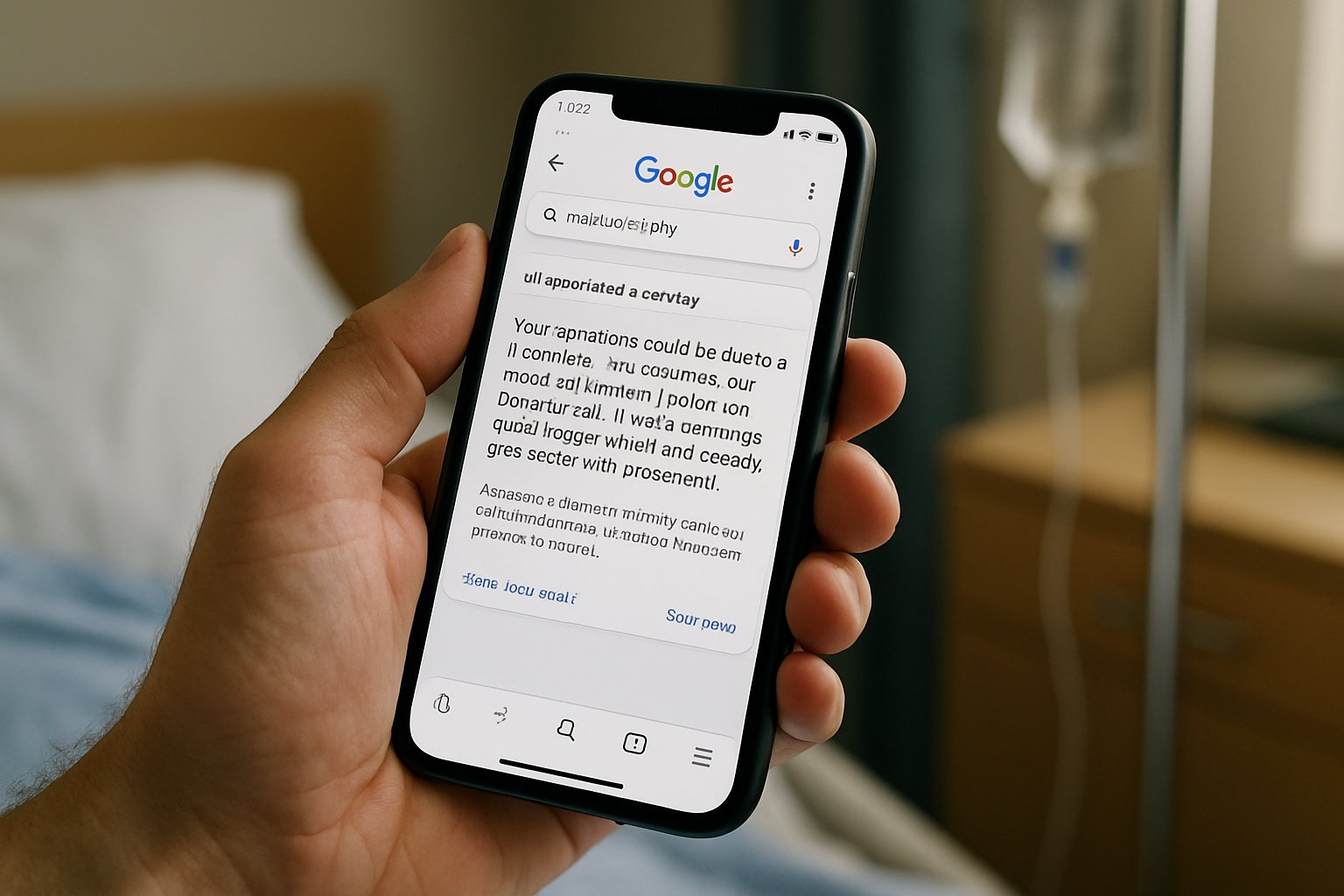
Charities including Pancreatic Cancer UK, British Liver Trust, and Marie Curie voiced alarm within hours. They argued that inaccurate summaries could delay doctor visits and escalate patient harm. Clinicians noted Google AI Overviews often changed wording between refreshes, compounding confusion. Google responded that many shared screenshots lacked context but promised rapid quality reviews. Nevertheless, the company released no verifiable correction log.
These documented failures illustrate real clinical stakes. Consequently, scale becomes the next critical factor.
Prevalence And Exposure Rates
Industry trackers reveal how often the feature appears across queries. Many enterprises track how often Google AI Overviews appears on their branded queries. Ahrefs estimated a 20.5 percent trigger rate in November 2025. Meanwhile, SEOClarity reported peaks nearing 30 percent on U.S. desktop searches. Semrush and other vendors recorded comparable upward trends, especially for health information.
- Ahrefs: one in five queries display the summary.
- SEOClarity: up to three in ten U.S. desktop results show the feature.
- SparkToro: fifty-eight percent of searches end without external clicks to publishers.
Mobile devices exacerbate the effect, because the summary occupies nearly the entire first screen. Users must scroll considerably before seeing organic links or government guidance. In urgent scenarios, that friction discourages deeper research.
Zero-click behavior magnifies the danger because users may trust a single overview. Google AI Overviews dominate the above-the-fold area, reinforcing that trust. Therefore, widespread exposure could amplify healthcare risks at population scale.
Prevalence data sets the context for clinical evaluation. Next, we examine specific safety mechanisms.
Major Clinical Safety Concerns
Medical researchers detail five recurring pitfalls of large language models in care. Google AI Overviews belong to the YMYL category demanding strict evidence standards. Hallucinations top the list, producing confident yet false statements. Additionally, overviews lack patient context, ignoring age, sex, or comorbidities. In contrast, clinicians tailor guidance using laboratory units and personal history.
- Hallucinated facts mislead decision making.
- One-size ranges hide abnormal labs.
- Bias may worsen health disparities.
- Volatile outputs hinder reproducibility.
- Lack of audit trail complicates liability.
Peer-reviewed studies in J Clin Med highlight limited external validation for medical chat systems. Moreover, researchers caution that benchmark success does not equal bedside safety. Regulatory authorities have yet to issue binding standards for generative answers in diagnostics.
UK charities operate helplines that field misinformed callers daily. Staff members now monitor generative search outputs to pre-empt dangerous misconceptions. They report escalating confusion over laboratory thresholds published without context. Subsequently, training costs rise as organizations update scripts with immediate corrections.
These issues converge under the label patient harm, emphasized by every quoted charity. Furthermore, inaccurate summaries can dissuade urgent hospital visits, as Mind observed with mental-health searches. Google stated it applies higher YMYL standards yet provided no third-party verification.
Without transparent metrics, professional trust erodes. Economic dynamics further complicate the debate.
Economic And Ethical Fallout
Publishers complain that overviews copy their reporting while reducing referral traffic. They contend that Google AI Overviews appropriate their headlines without adequate attribution. Rolling Stone’s owner even filed suit demanding compensation for content reuse. Moreover, fewer clicks shrink advertising revenue funding original journalism.
News organizations report traffic drops between five and fifteen percent after the feature appears. Consequently, some outlets cut investigative budgets, indirectly affecting public health coverage.
Ethical critics argue unchecked deployment shifts accountability from expert authors to opaque algorithms. In contrast, Google highlights citation cards intending to reward sources. However, studies show many readers never open those links. Unverified health advice erodes public trust in digital medicine.
Revenue tension pressures Google to accelerate but also to contain mistakes. The next section explores possible safeguards.
Mitigation And Audit Steps
Independent audits remain the gold standard for medical technology evaluation. Researchers propose sampling hundreds of health queries and scoring clinical accuracy. Consequently, regulators could establish acceptable error thresholds before public release.
Google could publish query-level dashboards displaying correction counts and response revisions. Furthermore, version control would help clinicians trace changes over time. Charities recommend on-page disclaimers urging users to verify critical health advice with professionals.
Legal experts propose classifying algorithmic health answers as medical devices under existing regulations. In contrast, tech policy groups prefer voluntary codes supplemented by transparency reports.
Below are priority actions for stakeholders.
- Commission third-party clinical audits within ninety days.
- Release anonymised error databases for transparency.
- Implement user feedback buttons on every overview.
- Delay expansion into new domains until Google AI Overviews metrics improve.
Improved guardrails must activate before Google AI Overviews surface any sensitive result. Structured oversight could curb inaccurate summaries and reduce patient harm. Finally, professionals can prepare by strengthening personal competencies.
Public health agencies can launch campaigns explaining safe search practices. For example, banners could encourage second opinions from accredited sites. Additionally, browser plugins might flag unverified statements within generated answers. Such nudges mirror vitamin labels that highlight recommended daily allowances. Effective governance will likely blend regulatory enforcement with agile internal monitoring.
Key Professional Development Pathways
Healthcare leaders must understand both generative AI mechanics and evidence appraisal. Clinicians with foundational AI literacy can spot dangerous outputs faster. Professionals can enhance their expertise with the AI+ Foundation™ certification. Understanding how Google AI Overviews compose answers equips clinicians to audit outputs effectively.
Moreover, journal clubs that compare overviews against peer-reviewed guidance build communal vigilance. Subsequently, institutions should integrate search auditing into quality improvement curricula. These steps position teams to navigate evolving healthcare risks confidently.
Continuous learning stays essential as models iterate weekly. The conclusion recaps actionable insights.
Google AI Overviews promise convenient synthesis yet carry measurable danger. Guardian reporting exposed clear clinical misfires involving diet, lab values, and cancer screening. Furthermore, prevalence data indicates millions may encounter those inaccurate summaries daily. Publishers face economic strain, while charities warn of patient harm. Nevertheless, transparent audits, stronger guardrails, and skilled professionals can reduce unfolding healthcare risks. Therefore, readers should demand accountability and pursue certifications that sharpen critical AI literacy. Act now by reviewing the recommended certification and implementing the audit steps outlined above. Continued vigilance will determine whether search innovation truly supports clinical outcomes.



