AI CERTS
4 months ago
Gemini RAG capabilities power File Search API
In contrast, we will compare the managed approach against custom retrieval stacks. Furthermore, readers will find actionable advice for compliance, cost control, and skill development. Finally, certifications like the AI Developer credential appear where deeper expertise is required.
Gemini Launch Overview Details
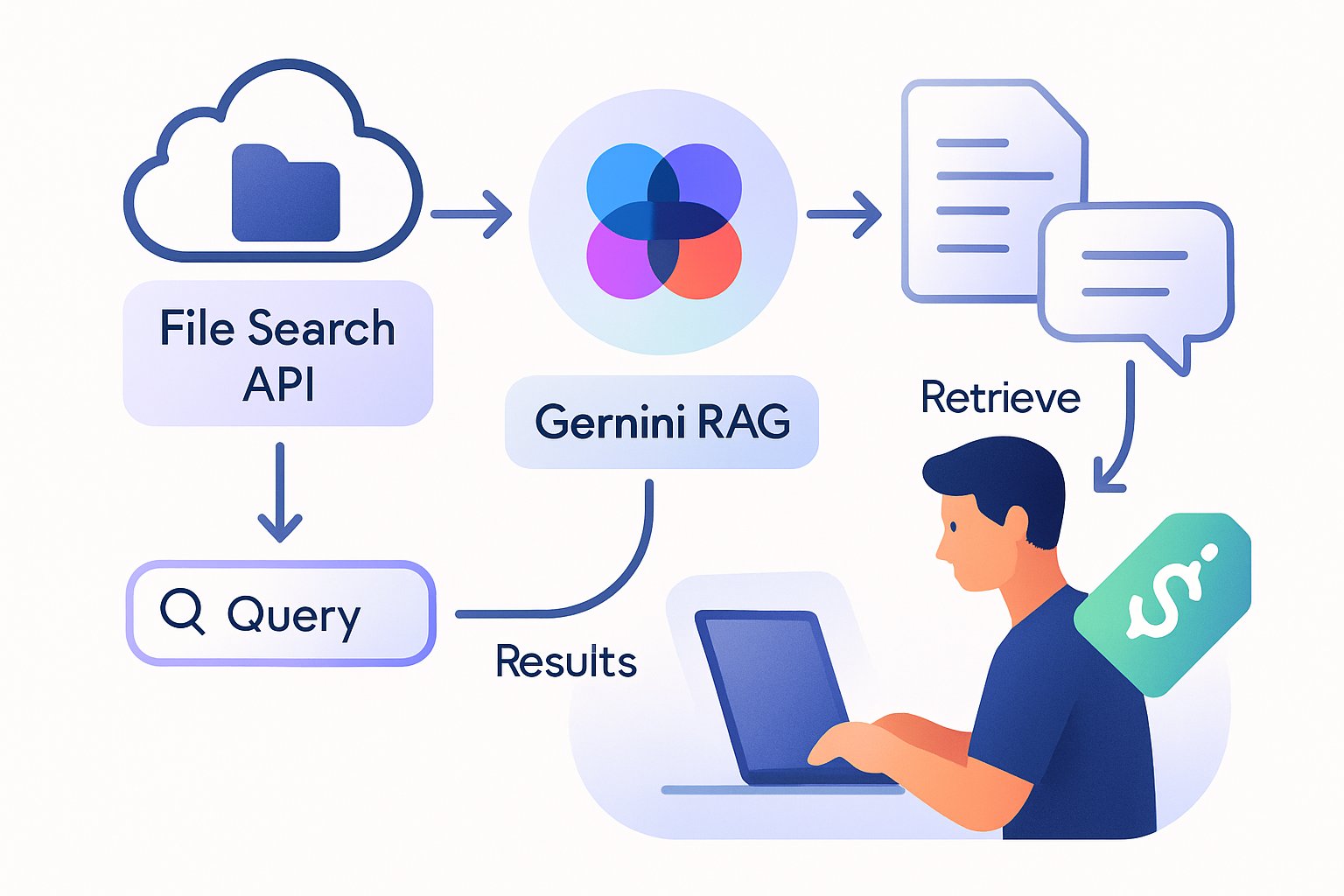
Google publicly previewed the File Search Tool during its developer blog post on 6 November 2025. Meanwhile, release notes confirmed immediate availability in the Gemini API console and AI Studio. Developers can upload PDF, DOCX, TXT, JSON, and many code formats up to 100 MB. Moreover, each project receives ten stores, with free tier storage capped at 1 GB. Higher tiers scale storage to 1 TB, yet Google suggests 20 GB stores for stable latency. Notably, Gemini RAG capabilities underpin the tool's semantic matching. Subsequent documentation supplied quickstart code samples in Python, JavaScript, and REST. Key launch numbers clarify viability for many workloads:
- $0.15 per million tokens during indexing
- Query embeddings and storage incur no extra charge
- 100 MB maximum individual file size
- Free tier includes 1 GB total store capacity
Consequently, early coverage from Android Central and TechBriefAI highlighted the predictable $0.15 indexing fee. Additionally, early adopter Beam reported sub-two second retrieval for thousands of daily queries. Robust document AI analysis remains vital during ingestion of scanned legal contracts. These data points show Google targeting production assistants rather than experimental demos. Therefore, the launch positions Gemini RAG capabilities as an enterprise-ready pillar inside Google's stack. Developers watched live demos that indexed thousands of pages in minutes.
Key Pricing Model Breakdown
Cost clarity sets the File Search API apart from several rival vector services. Moreover, developers pay only when embeddings are created, avoiding ongoing vector costs per query. This shift moves spend from unpredictable retrieval fees to an upfront capitalization event. Consequently, teams with heavy read patterns can forecast budgets more precisely. In contrast, custom Pinecone stacks charge storage plus query units, complicating estimation. Furthermore, retrieved tokens still count as normal Gemini context tokens, so generation traffic remains material. However, the ability to tune chunk size can minimize irrelevant context expansion. Developers should track how often their system updates documents, because re-indexing triggers new embedding costs. Therefore, pilot projects must model update frequency alongside query volume. Benchmarking Gemini RAG capabilities against planned workloads will reveal the true total ownership cost. Organizations should still model token expansion because long answers can multiply context size. Regulatory environments may also influence allowable embedding refresh cycles.
Core Technical Workflow Steps
The workflow mirrors classic retrieval-augmented generation pipelines yet removes operational overhead. First, developers create a FileSearchStore within the Gemini console or via REST. Then, files upload through the Files endpoint, creating temporary raw objects lasting 48 hours. Subsequently, gemini-embedding-001 chunks each document and writes vectors into the store. During query time, generateContent references the store name and automatically injects matched chunks. Consequently, the model replies with cited passages and optional grounding metadata. Moreover, the same call works in Python, JavaScript, and REST, easing multi-stack integration. This simplicity accelerates prototyping, yet careful evaluation remains essential. Gemini RAG capabilities therefore abstract vector math behind a single API flag. Latency typically stays under one second for small stores, according to internal benchmarks. Consequently, user experience remains responsive even during bursty traffic.
Document AI Analysis Factors
Certain documents demand deeper document AI analysis before indexing. For example, medical PDFs with complex tables may confuse the default parser. Consequently, teams should apply OCR or layout detection pre-processing when accuracy matters. Additionally, Gemini RAG capabilities support code files, yet binary diagrams still require conversion. Therefore, create validation suites that compare retrieved snippets against ground truth benchmarks. Effective document AI analysis tools can pre-classify page structures before vectorization.
Key Grounding Metadata Insights
Grounding metadata allows auditors to trace every response back to original text chunks. Moreover, enabling citations encourages user trust and simplifies regulatory review. However, storing embeddings indefinitely raises governance questions around retention policies. Organizations may need purge workflows or region-restricted stores to stay compliant. Consequently, legal teams must participate early during architecture reviews.
Major Benefits For Developers
The managed nature of the service eliminates several infrastructure burdens. Moreover, Gemini RAG capabilities integrate with AI Studio, enabling quick testing without backend code. Additionally, the model can return relevant snippets in under two seconds according to Beam. These strengths translate into clear advantages:
- No separate vector database to deploy or scale
- Automatic chunking tuned to Gemini token limits
- Built-in citations through grounding metadata
- Predictable one-time embedding expenditure
- Native security model with Google Cloud IAM
Early adopters report support ticket deflection gains exceeding 40%. As a result, customer satisfaction metrics improved without parallel headcount increases. Consequently, small teams can launch knowledge assistants within days rather than months. Furthermore, professionals can deepen mastery through the AI Developer™ certification. Therefore, skill investment complements platform convenience for long-term career growth. These benefits demonstrate how cost and velocity align under this managed model. However, understanding trade-offs remains critical before large scale adoption.
Key Risks And Limitations
No solution is free from constraints, and File Search is no exception. In contrast, self-hosted RAG stacks may outperform Google on certain niche metrics. However, parsing failures with complex medical tables reveal current extraction gaps. Consequently, healthcare or legal teams must conduct stringent doc audits. Data residency rules vary across regions, and some enterprises require strict in-country storage. Nevertheless, Google has not yet published a detailed regional compliance matrix. Moreover, embeddings are proprietary, raising vendor lock-in concerns when migrating data. Additionally, retrieved context tokens still trigger model charges, which can inflate costs silently. Therefore, periodic billing reviews should compare spend against expected baselines. Meanwhile, privacy teams should examine retention durations and delete policies for sensitive corpora. These issues underscore due diligence requirements. Consequently, balanced evaluation ensures Gemini RAG capabilities serve business goals responsibly.
Google's latest release cements Gemini RAG capabilities as a core platform feature for enterprise AI builders. Moreover, the managed file search API amplifies Gemini RAG capabilities and streamlines retrieval-augmented generation while introducing governance questions. However, careful planning around cost, privacy, and complex layouts remains essential. Consequently, teams should prototype, benchmark, and validate before full migration. Meanwhile, independent benchmarks are expected in early 2026. Professionals can validate skills through the AI Developer™ certification. Therefore, explore the API today and secure future-proof expertise.



