AI CERTS
3 months ago
Amazon’s document processing expansion doubles Bedrock capacity
Meanwhile, teams can feed structured outputs directly into RAG workflows through seamless Knowledge Bases integration. This article explains limits, pricing, caveats, and strategy for leaders evaluating Bedrock. Furthermore, each section offers engineering tips grounded in AWS documentation and field reports. Realizing value depends on leveraging the document processing expansion with disciplined engineering.
Why Limits Shifted Up
AWS moved Bedrock Data Automation to General Availability in March 2025. In contrast, customers soon requested bigger single file support. Therefore, Amazon engineers raised the upper bound through new splitter optimizations. The change delivered the widely publicized 1500 to 3000 page increase. Consequently, legal teams can ingest entire procurement manuals without external preprocessing.
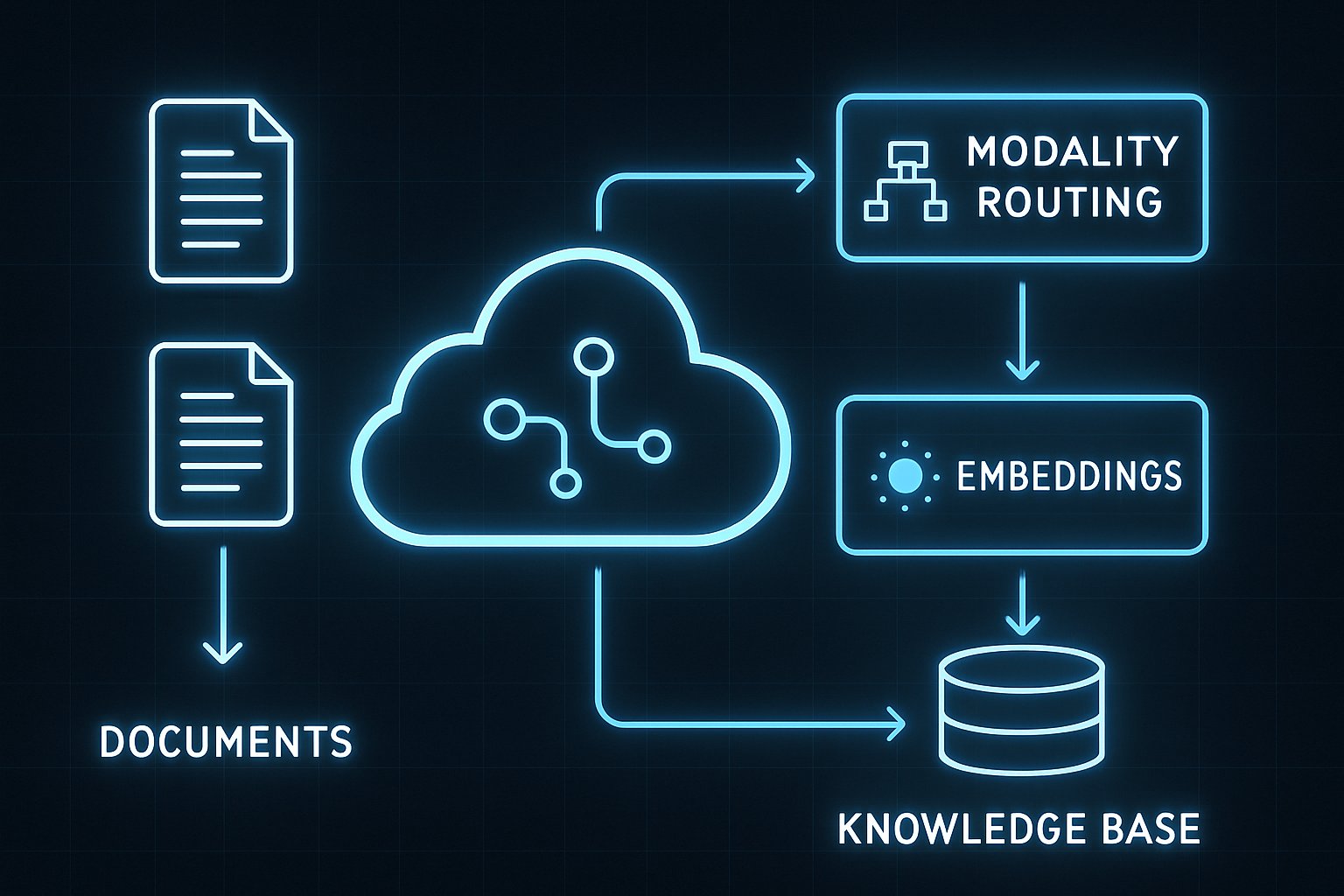
Nevertheless, console uploads remain restricted to 20 pages for interactive testing. Developers must call the workflow API to unlock the full ceiling. Moreover, the API automatically slices large PDFs and parallelizes inference. This adjustment underpins the document processing expansion roadmap. Subsequently, AWS highlighted reduced pipeline complexity as the key customer benefit.
These timeline details show why the size limit shifted so quickly. However, features beyond scale matter even more, so let us inspect them next.
Core Feature Additions Today
Beyond capacity, Bedrock added modality routing to control which assets are processed. For instance, engineers can skip audio when only text analysis matters. Additionally, hyperlink embedding extracts and stores every clickable reference inside PDFs. Consequently, knowledge graphs retain provenance for downstream audit trails. Overall, the document processing expansion pushes Bedrock beyond legacy OCR capabilities.
Moreover, outputs flow into Knowledge Bases integration with zero additional code. The service writes both standard and custom schemas directly to S3. Standard output costs roughly $0.01 per page according to AWS pricing. Conversely, custom blueprints cost $0.04 per page for thirty fields or fewer. Therefore, budgeting remains straightforward for finance stakeholders.
Altogether, these additions move Bedrock from experimental tool to comprehensive pipeline backbone. Nevertheless, financial clarity warrants deeper inspection, so the next section reviews numbers.
Pricing And Cost Details
Pricing often dictates adoption more than raw features. AWS publishes transparent examples for each mode. Consequently, leaders can forecast annual spend before migrating.
- Standard output: $0.010 per document page, billed on extraction completion.
- Custom blueprint: $0.040 per page for up to thirty fields, plus $0.0005 each extra field.
- Video analysis: $0.050 per minute for standard insights.
- Audio transcripts: $0.006 per minute, useful for call centers.
Additionally, storage and S3 egress fees still apply, though they stay minor at scale. Meanwhile, splitter jobs require sufficient Bedrock throughput quota. Teams should request increases weeks before large migrations. Therefore, run a proof of concept processing at least 100 pages. The dramatic 1500 to 3000 page increase can double spending if documents remain unchanged. Moreover, the document processing expansion means every extra page after optimization stays profitable. Budget planning must incorporate the document processing expansion to avoid surprise charges.
These numbers indicate competitive pricing compared with DIY Textract pipelines. However, operational caveats deserve equal attention, driving us to the next section.
Practical Usage Caveats Explained
Scale promises can mask subtle engineering pitfalls. For example, custom attribute extraction templates still support roughly twenty pages. Therefore, a compliance handbook may exceed that internal limit despite the overarching 1500 to 3000 page increase. In contrast, standard output handles the same handbook without issue. Additionally, complex tables convert best when the input file is PDF rather than DOCX.
Nevertheless, modality routing lets you bypass irrelevant images, cutting token usage. Moreover, hyperlink embedding sometimes fails if the source file contains layered vector art. Testing representative samples remains the safest strategy. Consequently, teams should create regression suites for every template. Ignoring subtleties can erode the gains promised by the document processing expansion.
These caveats underscore the gap between marketing and lived experience. Subsequently, we explore robust integration patterns to mitigate such risks.
Robust Integration Workflows Guide
Successful pipelines pair Bedrock with established AWS building blocks. Firstly, S3 buckets host raw and processed artifacts. Then, EventBridge triggers downstream Lambdas once extraction finishes. Furthermore, Knowledge Bases integration ingests summaries for retrieval augmented generation. Consequently, customer service chatbots can cite page level links confidently.
Security architects often activate KMS customer managed keys for both storage and API calls. PrivateLink keeps traffic inside your VPC, meeting strict governance demands. Additionally, writers can enhance skills through the AI Data Robotics™ certification. The program covers best practices for AI driven automation. Moreover, adoption journeys accelerate when staff understand policy constraints and quota management. Modality routing rules should live in version controlled configuration for auditability. That approach ensures the document processing expansion stays consistent across environments.
These workflow elements convert conceptual gains into operational reality. However, region rollout and compliance factors still influence final architecture decisions.
Governance And Region Rollout
Bedrock Data Automation launched in us-east-1 and us-west-2. Since mid 2025, Europe and Asia Pacific regions joined the roster. Therefore, sovereignty minded enterprises gain onshore processing paths. Nevertheless, some financial regulators still demand local residency audits. Consequently, you must confirm every data flow before final sign off.
Quota variability also appears across partitions according to community reports. Additionally, sudden throttling can disrupt big batch jobs crafted for the 1500 to 3000 page increase. Proactive service limit tickets mitigate that risk. Moreover, enable detailed CloudWatch dashboards to monitor errors per thousand pages. Policy teams should document how the document processing expansion aligns with regional data rules.
These governance steps protect large document investments. Finally, we can summarize strategic outcomes.
Strategic Impact Summary Insights
Amazon has transformed industrial content handling through the document processing expansion. Consequently, enterprises can consolidate workflows once fragmented across OCR, scripting, and manual review. Moreover, modality routing, hyperlink embedding, and Knowledge Bases integration create fertile ground for intelligent search. Nevertheless, success demands attention to console limits, pricing nuance, and regional governance. Therefore, teams should prototype with representative data and monitor quota metrics closely. Professionals seeking deeper mastery can pursue the AI Data Robotics™ certification to formalize skills. Ultimately, the document processing expansion empowers organizations to unlock insights hidden in colossal archives. Act now to modernize your document pipelines and stay competitive.



