
AI CERTs
2 days ago
Alibaba Qwen 3.5: Efficient Architecture for Enterprise AI
Global AI observers watched Alibaba release Qwen 3.5 last week. Consequently, the model’s performance headlines spread fast across engineering chats. The launch spotlights an Efficient Architecture that promises frontier power without frontier bills.
Meanwhile, enterprises still recall past over-hyped releases. Therefore, they demand proof that this Efficient Architecture really delivers. This article dissects Alibaba’s claims, system tricks, and red flags for technical buyers.
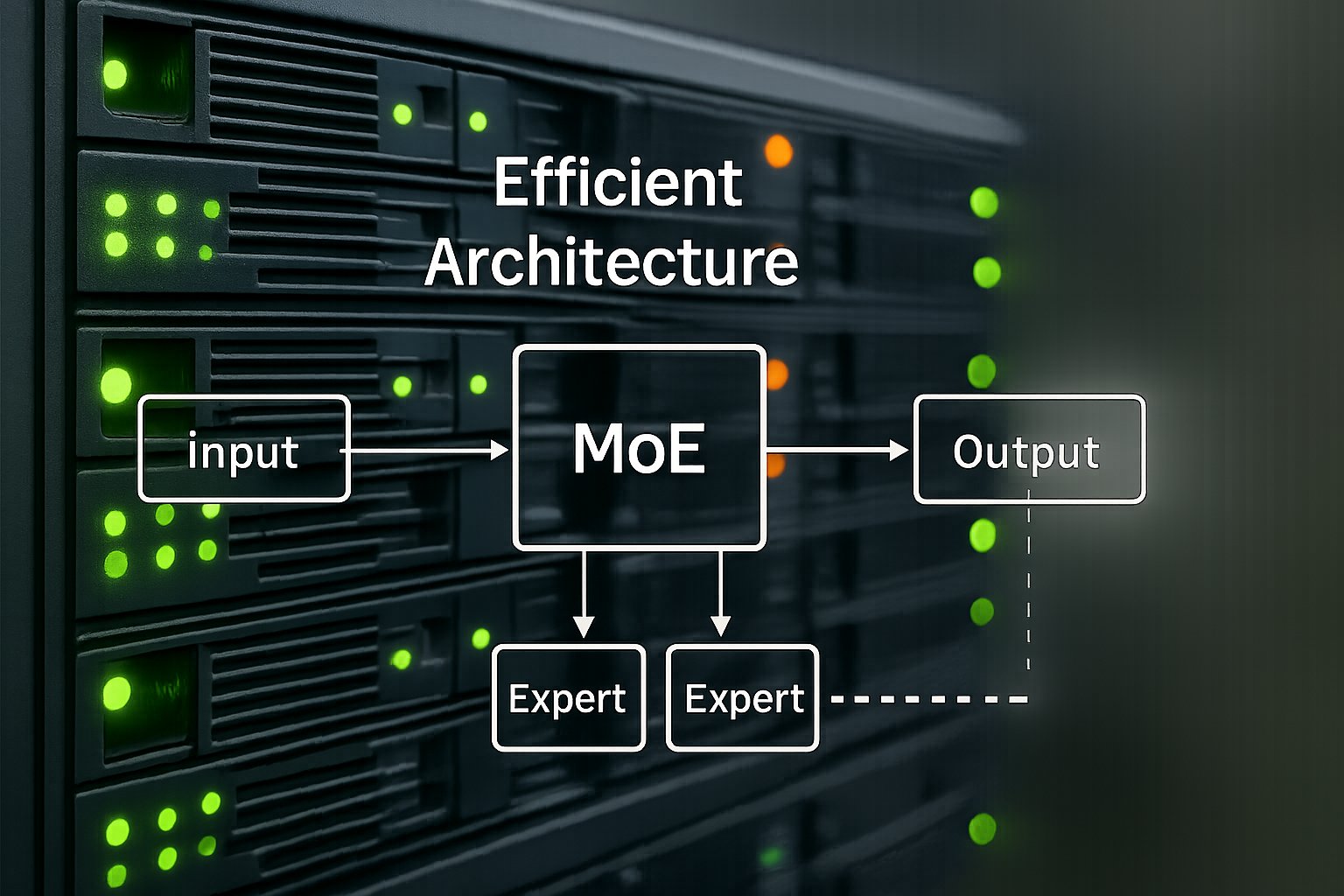
Headline Efficiency Claim Overview
Alibaba positions Qwen 3.5 as a 397-billion-parameter giant with only 17 billion active during inference. Moreover, the Efficient Architecture leverages sparse MoE routing, letting most parameters sleep each pass. VentureBeat reports 8.6× to 19× decoding throughput gains versus Qwen Max.
Additionally, Alibaba cites a 50% activation-memory drop from an end-to-end FP8 pipeline. In contrast, previous generations stayed at FP16. These numbers imply sizeable GPU savings for long-context processing.
However, independent evaluations remain pending. Third-party leaderboards will verify whether the Efficient Architecture sustains advertised speed under diverse loads. These verification steps matter before procurement.
Key takeaways: public metrics look impressive, yet community tests must confirm durability. Consequently, deeper technical design warrants inspection next.
Inside MoE Design Details
The model’s core uses an MoE layer stack with up to 512 experts, according to press notes. Each token triggers a gating network that selects minimal experts, sustaining the Efficient Architecture pattern. Furthermore, Gated Delta Networks replace standard attention, giving near-linear scaling to million-token contexts.
Open Weights under Apache 2.0 let teams audit the MoE implementation directly. Nevertheless, routing imbalance can stall GPUs when hot experts overload specific cards. Therefore, Alibaba pairs rollout router replay and speculative decoding to smooth traffic.
Researchers warn that such MoE systems need dynamic balancing logic. Alibaba claims internal schedulers solve this issue, yet skeptics await open benchmarks. These architectural insights lay groundwork for evaluating system optimizations.
Summary: sparse expert routing underpins cost cuts, but balancing remains tricky. Subsequently, system-level tweaks decide real throughput.
System Optimizations And Impact
Beyond MoE, several engineering choices reinforce the Efficient Architecture goal. Firstly, multi-token prediction accelerates generation by batching steps. Secondly, an FP8 pipeline halves activation memory while adding over 10% speed.
Moreover, speculative decoding offers early-exit shortcuts for simpler prompts. Consequently, response latency drops without harming reasoning quality. Alibaba also exposes three “thinking budget” modes, allowing callers to trade chain-of-thought depth for speed.
The hosted Qwen 3.5-Plus variant supports one-million-token windows. Meanwhile, self-hosted Open Weights cap at 256 K. Early users report that eight H100 GPUs with 512 GB RAM handle quantized inference comfortably.
- 8.6×–19× throughput gains over Qwen Max
- ~60% cheaper runtime, per vendor math
- 50% activation-memory reduction via FP8
- 1 M token context in hosted tier
These optimizations reinforce earlier efficiency claims. However, cost savings depend on pricing, which the next section analyses.
Key point: software tricks amplify hardware utilization, yet pricing determines perceived value. Therefore, cost math follows.
Pricing And Cost Math
Alibaba Cloud Model Studio lists Qwen Plus at USD $0.40 per million input tokens under 256 K. Consequently, similar workloads on closed models often cost 2-4× more. Output tokens price higher, yet remain competitive.
Furthermore, aggressive pricing combines with the Efficient Architecture to shrink total cost of ownership. Analysts suspect subsidies, but customers still benefit today. In contrast, self-hosting needs substantial VRAM, partially offsetting savings.
Open Weights enable on-prem deployment where cloud movement faces regulatory Flags. Nevertheless, hardware spending must be considered in any ROI spreadsheet. Enterprises should model token volumes, context lengths, and output ratios before deciding.
Takeaway: hosted pricing looks disruptive, although real savings hinge on workload patterns. Consequently, buyers must weigh deployment risks.
Deployment Flags And Risks
Operational Flags surface once engineers move beyond benchmarks. Memory footprint remains high because total parameters still occupy GPU shards. Moreover, MoE load imbalance can spike latency during traffic bursts.
Regulators may question data residency when using a China-based provider. Therefore, several EU firms prefer Open Weights on sovereign clouds. Additionally, early adopters found that quantization plus expert parallelism demands mature orchestration skills.
Benchmark tables also raise Flags. Vendor-curated tests seldom mirror messy production prompts. Independent labs will stress-test longer chains, multi-modal inputs, and adversarial queries.
Section summary: technical and geopolitical Flags complicate adoption. However, competitive dynamics push many firms toward evaluation anyway.
Market And Competitive Landscape
Qwen 3.5 targets the same customers considering GPT-5.2, Gemini 3 Pro, and Claude Opus. Moreover, Alibaba argues that its Efficient Architecture lets firms “own and control” their stack. TechCrunch quotes developers celebrating the open option.
In contrast, investors debate whether overseas skepticism will limit reach. Nevertheless, low prices pressure Western vendors to revisit their tariffs. MoE efficiency stories now appear in many product roadmaps across vendors.
Furthermore, the expanding 201-language vocabulary positions Qwen for emerging markets. Consequently, non-Latin scripts see fewer tokens, saving money again.
Key insight: competition intensifies on both capability and price fronts. Subsequently, skills development becomes strategic.
Skills And Next Steps
Engineering teams need new expertise to exploit this Efficient Architecture. Routing diagnostics, expert parallelism, and FP8 tuning top the list. Professionals can enhance their expertise with the AI Product Manager™ certification.
Moreover, architects should pilot quantized Open Weights on sandbox clusters. Consequently, they will measure tokens-per-second, memory ceilings, and cost per million tokens. Documentation of red Flags during pilots will guide production rollout.
Finally, watch community leaderboards for updated benchmark scores. Independent confirmation will either validate Alibaba’s narrative or expose gaps.
Summary: investing in upskilling and controlled pilots reduces risk. Therefore, the conclusion pulls these threads together.
Conclusion
Alibaba’s Qwen 3.5 pairs an Efficient Architecture with sparse MoE, FP8, and linear attention to challenge incumbents. Moreover, aggressive pricing and Open Weights widen its appeal. Nevertheless, memory demands, routing balance, and regulatory Flags require careful evaluation.
Consequently, teams should pilot workloads, track independent benchmarks, and build MoE expertise. Explore certifications, refine cost models, and engage cross-functional stakeholders. Take the next step and turn efficiency promises into tangible enterprise value today.



