AI CERTS
5 months ago
Crawler Bypass Showdown: Cloudflare vs Perplexity AI Agents
Cloudflare accused Perplexity of spoofing Chrome user agents, rotating networks, and ignoring explicit do-not-crawl directives. Meanwhile, Perplexity insisted its agents executed only user-triggered fetches via the Browserbase cloud browser. The dispute illustrates deeper tensions over revenue, copyright, and technical identity on the open web. Moreover, new commercial experiments like pay-per-crawl and cryptographic bot signatures are emerging. Together, they signal a future where every request carries a price or a proof token.
Crawler Bypass Arms Race
Cloudflare logged about 416 billion AI bot requests between July and December 2025. Meanwhile, more than 2.5 million sites opted to block AI training through Cloudflare's managed robots.txt controls. Wired reported that 88% of top news outlets now block AI crawlers. Consequently, the cost of content acquisition for large models keeps climbing. Publishers fear that unlicensed scraping will erode subscription revenue and ad referrals.
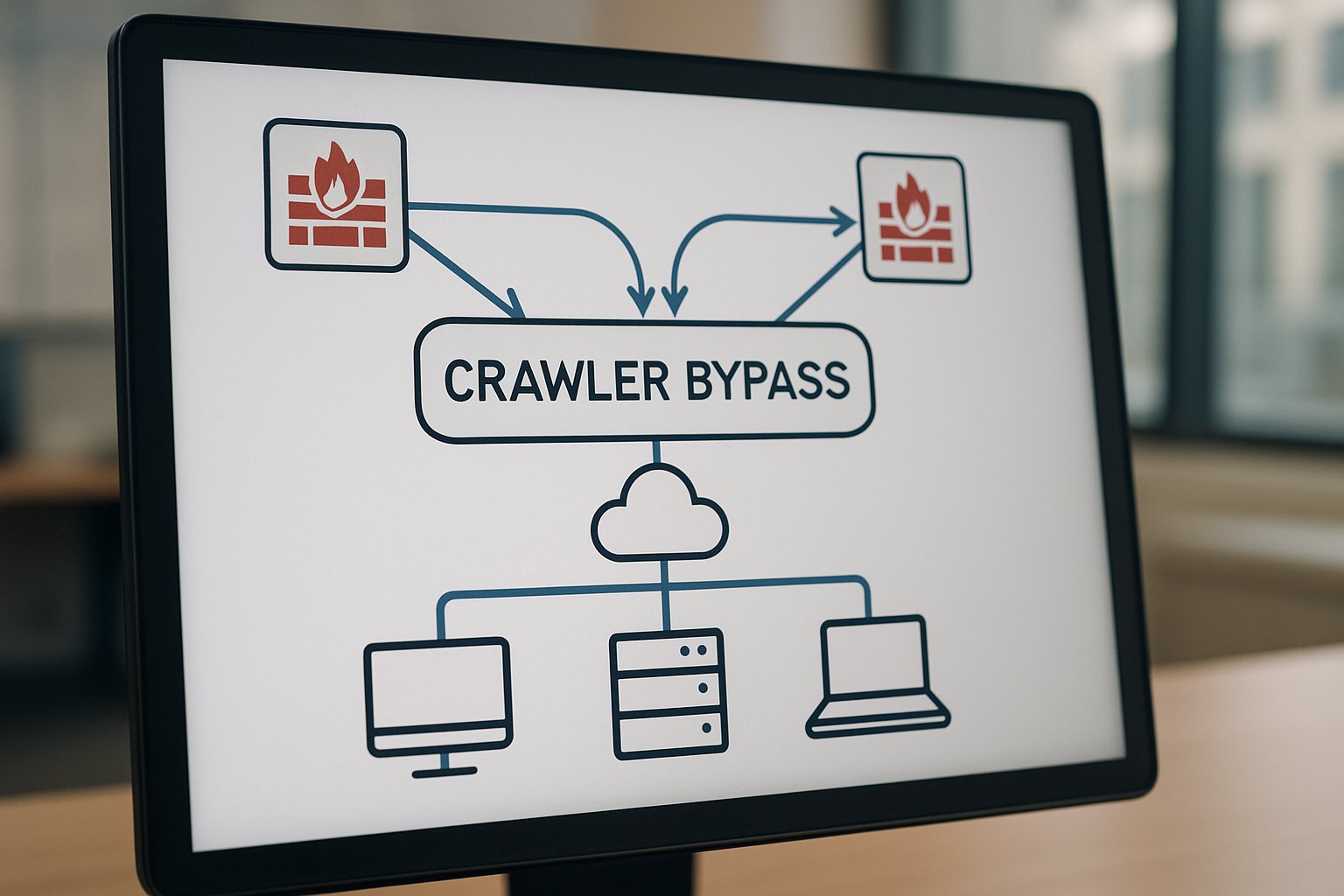
Developers still demand fresh data for real-time search answers. Therefore, agent vendors experiment with tactics that appear human, including headless browsers and IP rotation. In contrast, infrastructure providers deploy machine-learning fingerprints and signature headers to expose spoofing. The resulting tug-of-war defines the Crawler Bypass debate.
These numbers reveal a full-scale escalation between data seekers and gatekeepers. However, the story gained urgency after Cloudflare went public with specific accusations.
Cloudflare Raises Alarm
On 4 August 2025, Cloudflare published a forensic blog on the disputed traffic. The company split requests into declared and stealth classes, as its chart below shows. Stealth requests used a generic Chrome user agent and rotated autonomous system numbers. Moreover, Cloudflare claimed these requests ignored robots.txt directives, a hallmark of aggressive scraping. The blog labels the technique a dangerous Crawler Bypass pattern.
- 20–25 million declared requests daily
- 3–6 million stealth requests daily
- 88% top news outlets blocking AI bots
Consequently, Cloudflare de-listed Perplexity from its Verified Bots program and pushed new managed-rule signatures. Matthew Prince warned that internet economics could shift as pay-per-crawl experiments mature.
Cloudflare's evidence positioned the company as guardian of publisher intent. Nevertheless, Perplexity quickly contested both the numbers and the attribution, setting the stage for rebuttal.
Perplexity Rebuts Alarm Claims
Perplexity posted a rebuttal titled “Agents or Bots? Making Sense of AI on the Open Web.” The company argued that Cloudflare misidentified traffic that actually refers to Browserbase, a third-party cloud browser. Additionally, Perplexity insisted its service performs user-triggered fetches rather than bulk indexing. The blog stressed that agents operate in a different mode than traditional crawlers.
In this model, each fetch occurs after a live user initiates a search query. Consequently, the firm claims it stores no long-term copy of the fetched content. Perplexity warned that labeling such activity as scraping would suffocate innovation. The company portrayed Cloudflare's move as a weaponisation of infrastructure against startups following ethical guidelines.
Perplexity's statement reframed the argument around user agency and fair access. However, the firm offered limited logs, leaving questions about the alleged Crawler Bypass unanswered.
Technical Evasion Tactics Explained
Investigators highlight several low-level tricks that let agents pass as human browsers. For example, user-agent spoofing refers to setting headers that mimic recent Chrome versions. Moreover, IP rotation and ASN hopping scatter requests across many networks, frustrating simple blocklists. Stealth operators also toggle JavaScript rendering mode to bypass static checks.
- Spoofed browser user-agents
- Dynamic IP and ASN rotation
- Headless Atlas engine for full page rendering
Cloud browser services such as Browserbase expose an Atlas rendering mode that executes complete Chromium sessions. Consequently, agents fetch ads, analytics, and dynamic content, making scraping fingerprints resemble real users. This realism turns a simple block into a sophisticated Crawler Bypass maneuver.
The tactics show that identity signals are easier to fake than behavioral consistency. Therefore, publishers require layered defenses combining signatures, rate limits, and cryptographic proofs.
Defensive Measures For Publishers
Cloudflare promotes Verified Bots, a scheme where crawlers sign every request with a secret key. Additionally, its managed robots.txt lets operators block AI tools by default, then whitelist paying clients. Pay-per-crawl experiments create a market that, Cloudflare argues, converts illicit scraping into licensed access.
- Web Bot Auth signature headers
- Machine-learning fingerprint detection
- Atlas throttling rules
Meanwhile, several publishers combine those tools with rate caps based on perceived user intent. In contrast, smaller sites rely on community WAF templates that reference common Crawler Bypass heuristics.
Professionals can enhance their expertise with the AI Ethical Hacker™ certification, which covers bot threat modeling.
Combined, these layers raise the cost of illicit access without harming legitimate search referrals. However, technical tools alone cannot settle the policy debate driving rapid escalations.
Policy And Business Impact
Legal scholars note that robots.txt refers to an advisory, not a binding, protocol. Consequently, ignoring it may lead to contract or copyright claims rather than traditional hacking charges. Publishers like The New York Times pursue licensing deals while reinforcing blocks against unapproved scraping.
Cloudflare's CEO argues that a pay-per-crawl business model could realign incentives for sustainable content production. Conversely, startups fear such a model favors incumbents with deep pockets. Moreover, regulators may scrutinize whether combined search and AI crawlers unfairly bundle markets.
The Cloudflare-Perplexity confrontation therefore becomes a bellwether for broader Crawler Bypass policy fights. Nevertheless, no clear consensus exists on balancing innovation and publisher control.
Revenue pressures ensure the dispute will intensify rather than fade. Subsequently, stakeholders are racing to craft open standards before lawsuits dictate outcomes.
Future Standards And Solutions
Several industry groups are drafting Web Bot Auth specifications that layer public-key signatures onto HTTP. Therefore, a verified bot could prove identity while requesting Atlas data sets under agreed terms. Cloudflare already tests such flows with selected partners.
OpenAI, Google, and Perplexity all monitor these pilots, though each operates in a different mode. In contrast, smaller projects explore decentralized metadata that attaches license terms directly to pages.
If adopted widely, these protocols could defuse some Crawler Bypass tensions by turning raw data into a metered resource. Standards work remains slow, yet economic urgency keeps pressure high. Consequently, enterprises that prepare now will gain leverage in future negotiations.
Publishers, infrastructure firms, and AI startups are now locked in a delicate standoff. Crawler Bypass strategies will continue evolving as long as fresh data fuels competitive AI experiences. Nevertheless, Cloudflare’s blocks, Perplexity’s defenses, and emerging standards show that transparency and verifiable identity can narrow the trust gap. Therefore, decision-makers should audit their bot traffic, benchmark protective layers, and join standards bodies shaping future access protocols. Professionals who master the security implications can steer these conversations. Consequently, consider pursuing the linked AI Ethical Hacker™ program to deepen your defenses and influence policy outcomes. Moreover, early adopters often gain negotiating power when licensing discussions finally materialize.
Disclaimer: Some content may be AI-generated or assisted and is provided ‘as is’ for informational purposes only, without warranties of accuracy or completeness, and does not imply endorsement or affiliation.



