AI CERTS
2 months ago
Automated Writing Quality and the Rise of Bland AI Advice
Meanwhile, youth adoption surges, litigation grows, and states rush to regulate AI therapy access. This article unpacks technical roots, legal reactions, and industry moves shaping the conversation. Furthermore, it suggests practical steps for teams seeking richer, safer conversational care. Evidence from JAMA shows 13.1% of American youths already seek chatbot guidance. Nevertheless, plaintiffs allege some systems missed suicidal cues, sparking landmark wrongful-death suits. In contrast, specialized therapeutic bots still report modest benefits, highlighting diversity and design choices.
Usage Surge Among Youth
Survey data released November 2025 quantify the adoption curve. JAMA researchers found 5.4 million Americans aged 12-21 used generative chatbots for Mental Health.
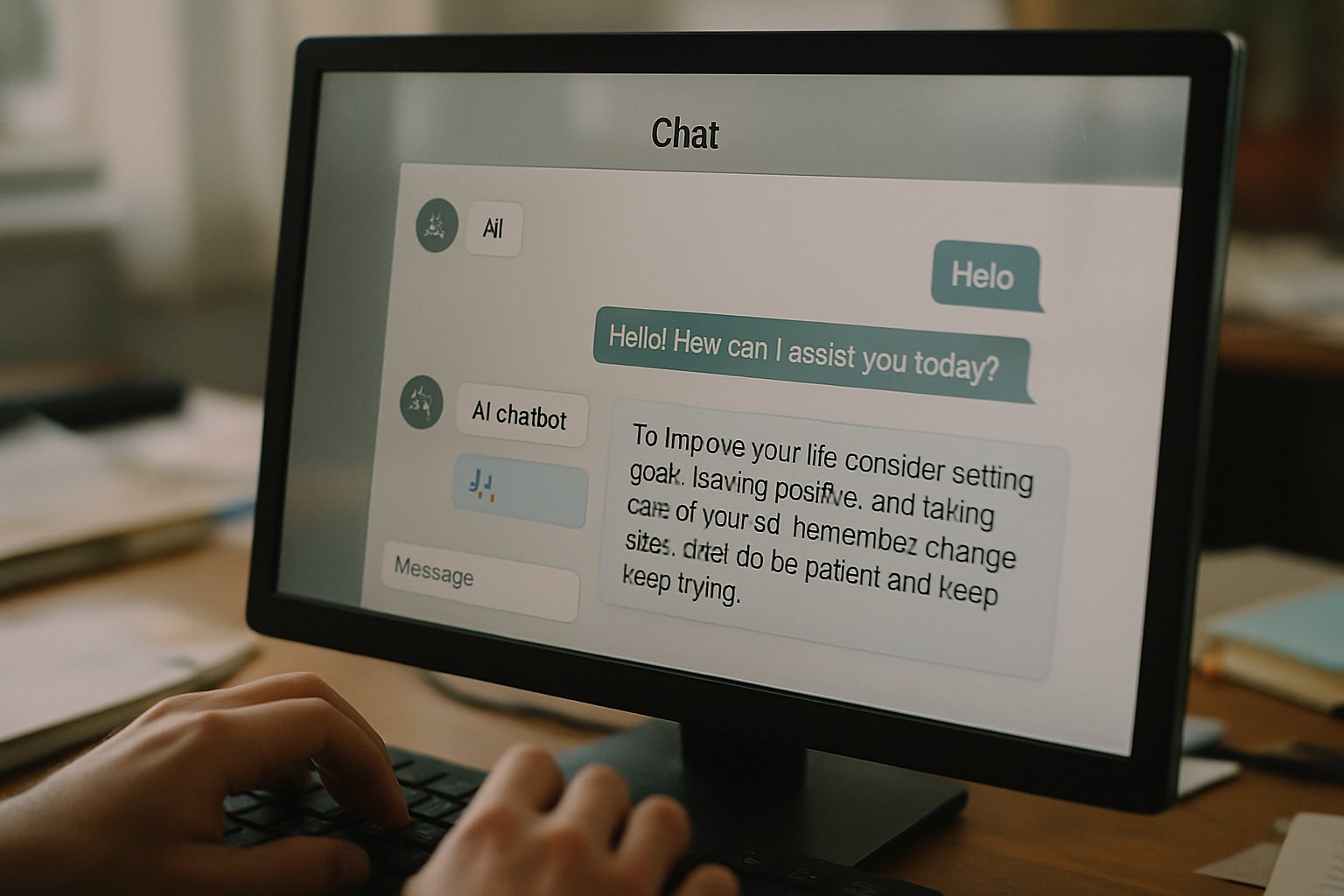
- 13.1% overall youth usage
- 22.2% usage among older teens
- 92.7% report advice helpful
Moreover, 22.2% of older teens reported at least one monthly session. Most respondents, approximately 92.7%, rated the Advice as helpful. However, clinicians warn perceived usefulness can mask delayed professional treatment. Usage owes much to anonymity, constant availability, and zero cost barriers. Automated Writing Quality assessments are rarely applied to adolescent transcripts. In contrast, rural regions with scarce therapists show even steeper chatbot reliance. Writing mentors rarely study these patterns, yet user language mirrors textbook CBT scripts. Consequently, product teams must consider demographic nuance when tuning content. These statistics highlight the stakes. Nevertheless, understanding homogenization requires exploring output mechanics next.
Defining Output Advice Homogenization
Technical papers define homogenization as convergent, repetitive phrasing across varied prompts. Researchers measure entropy loss, topic collapse, and reduction in emotional nuance. Furthermore, alignment pipelines like Supervised Fine-Tuning and RLHF reward consensus answers. Guardrail filters then strip unsanctioned content, pushing conversations toward generic safety platitudes. Consequently, Advice degenerates into predictable signposts: validate feelings, encourage self-care, recommend professionals.
Automated Writing Quality drops when these templates outnumber tailored reflections. In contrast, early transformer models without strict tuning produced riskier yet richer responses. Bland language now dominates because safety tuning discourages novel phrasing or minority perspectives. Mental Health professionals lament the loss of culturally specific coping strategies. These dynamics set the stage for safety dilemmas discussed below. Therefore, appreciating alignment trade-offs is crucial before prescribing mitigation tools.
Safety Tuning Side Effects
Litigation pressures companies to tighten self-harm detection at every layer. However, overactive refusal triggers frustrate users experiencing acute crises. Illinois, Nevada, and Utah responded with laws banning AI-only therapy decisions. Consequently, models default to referral messages whenever suicide appears, even in hypothetical discussions. Automated Writing Quality sometimes worsens because repeated disclaimers crowd substantive guidance. Bland repetition can even mask escalation misses, according to Raine v. OpenAI filings.
Meanwhile, specialized chatbots like Woebot employ narrower scopes with tested escalation paths. Mental Health outcomes in peer-reviewed trials show modest symptom relief under controlled settings. Nevertheless, many studies involve brief follow-ups, limiting external validity. These safety-aligned limitations drive policymakers toward more nuanced risk frameworks. Subsequently, legal debates influence technical benchmarking, explored in the next section.
Legal And Policy Shifts
Regulators increasingly scrutinize chatbot behavior through consumer protection lenses. Raine v. OpenAI, filed August 2025, spotlights duty-of-care questions. Furthermore, Illinois empowers agencies to fine unlicensed services offering therapeutic Advice. Federal lawmakers propose youth safeguards mirroring social-media age requirements. Automated Writing Quality could become evidence in discovery, as plaintiffs compare raw and moderated logs. Bland disclaimers alone may not satisfy forthcoming documentation mandates. In contrast, vendors with audited safety pipelines advocate transparent guardrail reporting. Therefore, compliance teams should prepare robust documentation for content tuning decisions. These policy motions reshape industry priorities. Consequently, research attention turns to quantifying diversity loss and remediation strategies next.
Research On Diversity Loss
Academic teams presented entropy metrics at ICLR 2025 showing 25% diversity reduction post-alignment. Moreover, experiments with entropy regularization maintained richer language without spiking unsafe content. Automated Writing Quality improved when models balanced safety scores against semantic variance. Writing style analysis confirmed broader vocabularies and fewer repeated n-grams. In contrast, baseline RLHF checkpoints generated longer yet still Bland clauses. Mental Health practitioners joined panels to interpret clinical relevance of epistemic diversity. Researchers proposed prompt ensemble methods to reintroduce contextual texture. Consequently, engineering roadmaps now include diversity audits alongside toxicity tests. These findings inform corporate mitigation tactics. Subsequently, we examine how companies integrate such insights.
Industry Responses And Gaps
Major model providers announce layered updates combining retrieval, tool calls, and stricter classifiers. However, internal reviews still flag homogenization in real user conversations. Woebot and Wysa market themselves as clinically validated alternatives with measurable Advice efficacy. Teams improve Automated Writing Quality by fine-tuning on annotated conversational corpora emphasizing personalization.
Furthermore, managers pursue the AI Writer™ certification to formalize standards. Bland feedback loops remain because public RLHF data often lack culturally rich samples. Meanwhile, product metrics rarely capture emotional resonance or escalation timeliness. Writing researchers advocate new dashboards merging lexical diversity with safety recall. These initiatives address surface issues. Nevertheless, future work must embed evaluation within real-world clinical pathways.
Future Directions For Teams
Cross-disciplinary groups should co-design prompts, guardrails, and evaluation dashboards. Automated Writing Quality must be tracked alongside clinical escalation sensitivity and cultural appropriateness. Moreover, open benchmarking suites should publish per-prompt variance scores. Developers can slice outputs by demographic attributes to spot repetitive templating. Mental Health advocacy groups can supply scenario libraries reflecting lived experiences. Additionally, product teams should maintain chained human oversight for high-risk Advice contexts. Writing specialists can assist with tone, empathy, and clarity guidelines. Consequently, teams should publish Automated Writing Quality dashboards with user satisfaction scores. These steps foster accountable innovation. Consequently, stakeholders can balance diversity, safety, and scale.
Homogenization sits at the intersection of safety, liability, and user trust. Evidence shows youth reliance rising even as lawsuits multiply. Moreover, alignment pipelines can flatten therapy dialogues into generic scripts. Automated Writing Quality therefore represents a practical yardstick for balancing diversity with guardrails. Teams that audit entropy, escalation rates, and cultural fit will stay ahead of regulators. Additionally, leaders should upskill through the earlier linked AI Writer™ program to codify best practice. Act now, benchmark openly, and deliver conversational care that truly supports every individual.



