
AI CERTs
2 months ago
Grok 3 Overtakes Coding Leaderboards Amid Benchmark Scrutiny
Developers woke up to unexpected leaderboard drama when Grok 3 Beta stormed public evaluations in February 2025.
Within hours, the model landed atop the LMSYS Chatbot Arena coding leaderboard, displacing long-time favorites from OpenAI and Google.
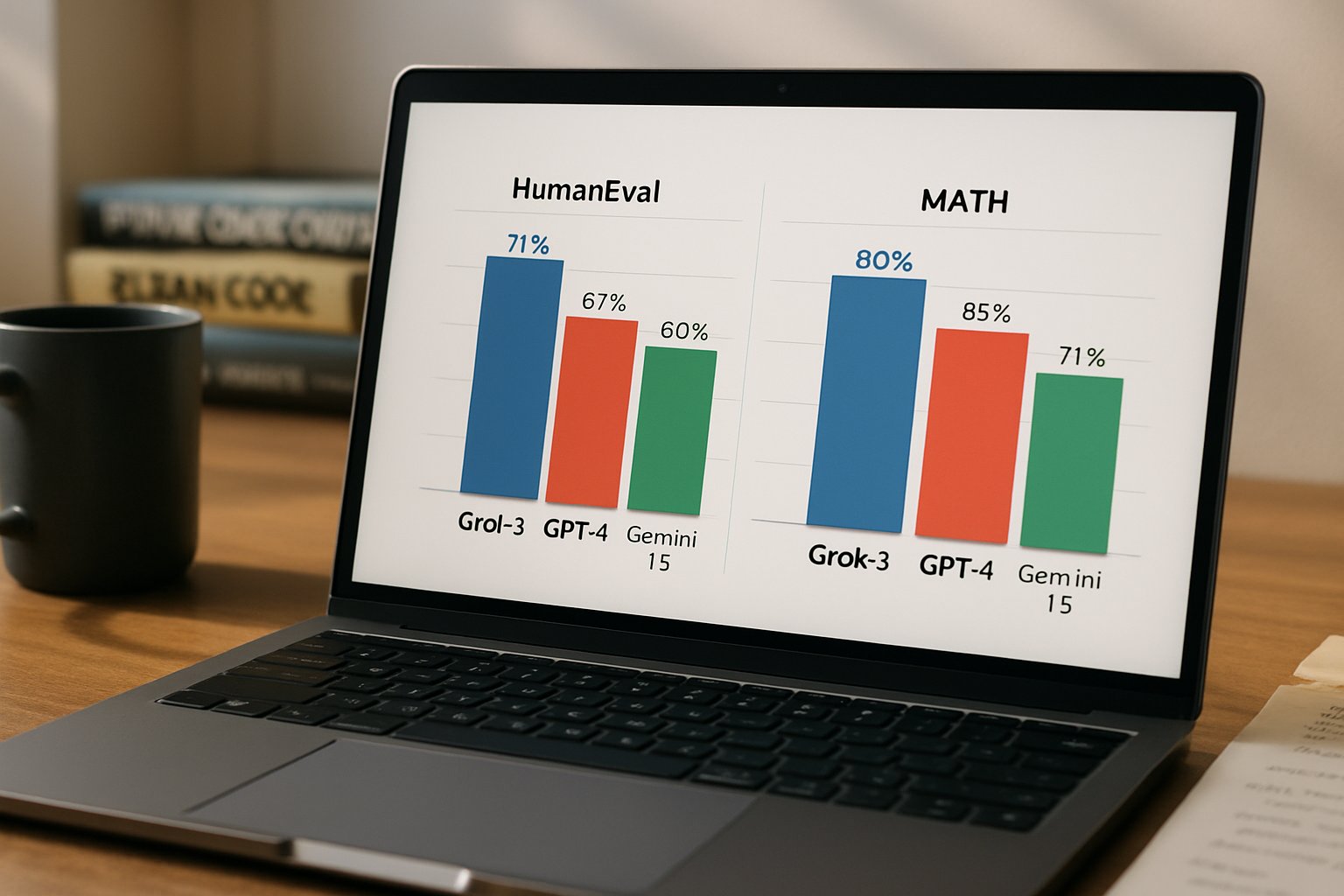
Industry feeds buzzed as xAI boasted an Elo score near 1400 and unprecedented long-context reasoning features.
Consequently, investors, engineers, and researchers scrambled to verify the claims and understand what the surge really meant.
This article dissects the launch impact, leaderboard mechanics, benchmark numbers, and emerging controversies surrounding Grok 3.
Launch Shakes Benchmark Charts
February 19, 2025 marked the public debut of Grok 3 Beta, delivered through xAI’s developer portal.
Moreover, the company reported a Chatbot Arena Elo of roughly 1402, positioning the release ahead of seasoned contenders.
User voting immediately reflected the hype; pairs featuring the newcomer won a decisive share in WebDev matches.
Consequently, headlines proclaimed a new standard for coding leaderboard supremacy, at least for that launch week.
These rapid gains excited developers. However, they also hinted at the volatility examined later in this analysis.
Early ranking dominance showcased public enthusiasm. Yet sustainable leadership required more than a launch-day spike.
Therefore, understanding the arena’s rating math becomes crucial.
Rating System Explained Simply
LMArena uses pairwise voting rather than fixed test sets to rank large language models.
Each anonymous round shows two answers for the same prompt, then crowds choose the better result.
Subsequently, an Elo-style algorithm converts win ratios into ratings, similar to competitive chess.
Tiny point shifts may reflect noise, because sample sizes vary and recent matches weigh heavily.
In contrast, sustained performance across thousands of votes suggests broader preference.
Consequently, Grok 3 enjoyed an immediate ratings boost, yet competition soon narrowed the margin.
Understanding this mechanism explains why daily coding leaderboard shifts are inevitable.
Next, the raw benchmark scores provide additional context.
Metrics Validate Technical Claims
Beyond crowd votes, xAI published formal evaluations highlighting reasoning and code generation gains.
Moreover, the company promoted a million-token context window supporting extensive document ingestion.
Key numbers include impressive LiveCodeBench results and top percentile math scores.
- AIME (math): 93.3% accuracy
- GPQA (science): 84.6% accuracy
- LiveCodeBench: 79.4% coding success
- Chatbot Arena Elo: ~1402 during launch
Furthermore, Grok 3 introduced a 'Think' mode that trades latency for deeper chain-of-thought reasoning.
These metrics impressed early testers like Andrej Karpathy, who tweeted that the model felt state-of-the-art.
Collectively, these scores suggested genuine advances. However, benchmarks alone never guarantee broad generalization.
Therefore, scrutiny soon shifted toward data practices fueling those numbers.
Controversy Around Data Tuning
July 2025 brought headlines when Business Insider revealed contractor projects aimed at improving Grok 3’s coding leaderboard rank.
Scale AI’s Outlier platform allegedly supplied curated prompts that mirrored WebDev arena tasks.
Consequently, critics warned of 'hillclimbing,' a practice that can overfit models to public tests.
Nevertheless, LMArena’s CEO argued that data collection through contractors represents normal model development.
Sara Hooker countered that ecosystem incentives may distort true progress when leaderboard prestige drives roadmaps.
Debate continues over acceptable tuning boundaries. However, transparency gaps complicate definitive assessments.
Meanwhile, rival models accelerated, intensifying leaderboard turnover.
Competitive Landscape Changes Daily
OpenAI, Google DeepMind, Anthropic, and others rapidly shipped updates after Grok 3’s debut.
Subsequently, new Gemini and Claude variants reclaimed the top coding leaderboard slots on several days.
In contrast, WebDev Elo gaps between first and fifth sometimes shrank to single-digit spreads.
Therefore, any banner declaring permanent supremacy risks aging quickly.
xAI responded with Grok 4 months later, highlighting the relentless iteration cycle now characterizing frontier research.
Rapid churn forces stakeholders to track trends continuously. Consequently, tooling and procurement processes must remain flexible.
These dynamics shape enterprise decision making, explored next.
Impacts For Enterprise Teams
Engineering leaders evaluate models not only by ratings but also by latency, cost, and policy compliance.
Moreover, volatile coding leaderboard shifts around Grok 3 can influence procurement timing and hedging strategies.
Consequently, many teams adopt multi-model routing, selecting the best performer for each task in real time.
Professionals can enhance expertise with the AI+ UX Designer™ certification, improving their evaluation and prompt-design skills.
Careful skill building mitigates hype cycles. Therefore, structured learning supports durable AI strategies.
Key takeaways follow below.
Strategic Takeaways And Outlook
Leaderboard wins attract attention, yet rigorous evaluation must blend live voting, formal tests, and real workload pilots.
Moreover, models like Grok 3 can lose positions quickly when rivals iterate or when sample sizes grow.
Consequently, procurement leaders should monitor uncertainty bands as closely as headline Elo numbers.
In contrast, immediate adoption without reproducible benchmarks risks technical debt and unexpected failure modes.
Nevertheless, continued progress remains undeniable; pairwise preference methods still offer valuable user-centric feedback.
Therefore, balanced governance, transparent reporting, and ongoing skills development will define sustainable large-scale deployments.
Looking ahead, analysts expect another release wave by mid-2026 that will reset every coding leaderboard again.
Enterprises that run internal benchmark pipelines can respond faster than slower competitors.
Moreover, adopting a portfolio of models hedges against sudden rank swings and enforces vendor accountability.
Consequently, leaders should revisit selection matrices each quarter, folding in fresh public and private data.
Meanwhile, practitioners can future-proof careers through certifications that sharpen design thinking and prompt engineering.
Ultimately, Grok 3’s rise and turbulence exemplify the new normal of perpetual change.



